Meta sort son modèle « frontière » Llama 3.1… ouvert, mais pas trop

Llama 3.1 est le nouveau très grand modèle de langage publié par Meta. L'entreprise revendique des résultats comparables aux modèles d'OpenAI GPT-4, GPT-4o et à Claude 3.5 Sonnet d'Anthropic. Mais elle met en avant avoir créé le premier modèle ouvert aussi puissant.
C'est d'un « 💥BOOM 💥 Llama 3.1 is out 💥 » sur LinkedIn (et sur X) que Yann LeCun, le vice-président de Meta et responsable scientifique des projets d'intelligence artificielle de l'entreprise, a annoncé, mardi 23 juillet, la mise à disposition du nouveau modèle de langage de Meta.
Qu'est-ce qui justifie cet enthousiasme alors que la nouvelle version de Llama ne sort pas avec un numéro « majeur » de version (3.1 et non 4.0) ?
Un modèle « frontière »
Dans son billet de blog accompagnant cette sortie, Meta met en avant plusieurs arguments. D'abord, Llama, avec ses 405 milliards de paramètres, est qualifié de « modèle frontière » par l'entreprise. Comme nous l'expliquions en novembre dernier, ce terme a été utilisé par OpenAI pour définir « des modèles de fondations très performants qui pourraient posséder des capacités suffisamment dangereuses pour poser de graves risques pour la sécurité publique ».
Mais contrairement à Anthropic et à OpenAI, Meta revendique avoir créé le premier modèle frontière « open source ». L'entreprise de Mark Zuckerberg s'est, depuis quelque temps, affirmée sur ce positionnement. Elle revendiquait le même qualificatif pour son modèle Llama-2. Mais des chercheurs ont remis en question cette utilisation du terme.
Un document très détaillé
Ici, avec Llama 3.1, Meta fait certains efforts en publiant, par exemple, une description détaillée du travail réalisé pour créer le modèle (.PDF), même si le texte n'est pas mis en ligne sur un serveur de preprint scientifique comme arXiv (ce qui lui aurait permis d'entrer réellement dans un processus de critique scientifique).
Ce document a le mérite de décrire le processus de pré-entrainement de Llama 3.1. Les chercheurs de Meta expliquent, par exemple, avoir utilisé des données publiées sur le web jusqu'à fin de l'année 2023 et des filtres heuristiques pour éliminer les documents de mauvaise qualité. Ils ont créé des processus différents pour extraire les données spécifiques au code et aux pages web relatives aux mathématiques.
Ils ajoutent aussi avoir fait subir les mêmes traitements de filtres de qualité pour les textes dans d'autres langues que l'anglais comme l'allemand, le français, l'italien, le portugais, l'hindi, l'espagnol et le thaï.
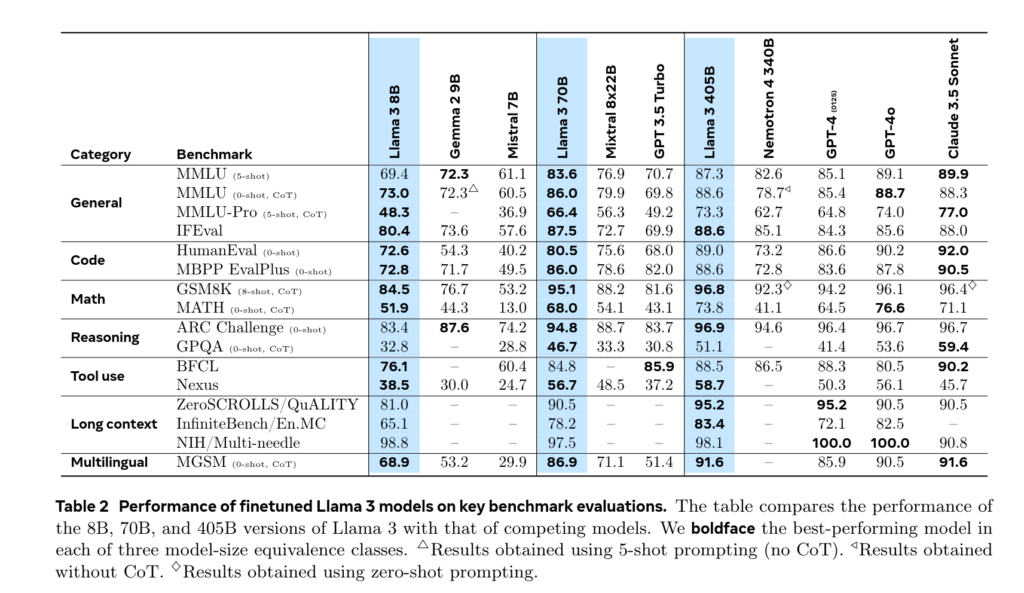
Le texte explique aussi comment et dans quels contextes des données « synthétiques » (c'est-à-dire générées par un modèle de données) ont été utilisées pour créer le modèle. Il détaille aussi les stratégies d'inférence utilisées et fourni des comparaisons de performances avec les autres modèles du même ordre :
Ouvert, vraiment ?
Par contre, contrairement à d'autres modèles qui se revendiquent « ouverts », Meta ne partage toujours pas les données d'entrainement et de pré-entrainement de son nouveau modèle et ne donne aucune information précise sur leur provenance.
La licence utilisée par Meta n'est pas claire non plus. Si l'entreprise explique avoir fait des modifications pour permettre aux développeurs d'utiliser ses modèles, contrairement à ce qu'elle insinue en parlant de modèle « ouvert », il faut d'abord remplir un questionnaire sur son site pour pouvoir y accéder.
De même, sur la plateforme d'hébergement de modèles Hugging Face, Meta explique que « vous devez accepter de partager vos coordonnées pour accéder à ce modèle ». Sur GitHub, elle ajoute qu' « une fois votre demande approuvée, vous recevrez une URL signée par courrier électronique. Exécutez ensuite le script download.sh, en transmettant l'URL fournie lorsque vous y êtes invité, afin de lancer le téléchargement ». Le modèle n'est donc pas si libre d'accès que ça, contrairement à ce que clame l'entreprise partout.
Pourtant, dans un billet de blog publié en parallèle, Mark Zuckerberg n'hésite pas à comparer la publication de ce modèle au passage des entreprises de la tech des systèmes Unix à Linux, en vantant l'ouverture de ce dernier. Le CEO de Meta va même jusqu'à affirmer qu'il croit « que l'IA se développera de la même manière ».
De futurs modèles multimodaux Indisponibles pour l'Europe
Mais contrairement à Linux, les utilisateurs européens ne pourront peut-être pas utiliser les futurs modèles de Meta. Une semaine avant de communiquer sur le lancement de son nouveau modèle, Meta a expliqué au média américain Axios qu'il ne proposerait pas ses futurs modèles « multimodaux » en Europe.
Si Llama 3.1 n'est pas multimodal (c'est-à-dire prenant en compte non seulement le texte mais aussi les images et le son), l'entreprise espère que ses prochains modèles le seront. Les chercheurs de l'entreprise notent dans leur texte que « nos modèles multimodaux sont en cours de développement et ne sont pas encore prêts à être diffusés ».
Mais l'entreprise évoque « la nature imprévisible de l'environnement réglementaire européen » pour expliquer sa décision. Pourtant, l'entreprise vise le RGPD, texte pourtant adopté il y a maintenant huit ans et non des textes plus récents comme l'AI Act.

Commentaires (3)
Abonnez-vous pour prendre part au débat
Déjà abonné ? Se connecter
Cet article est en accès libre, mais il est le fruit du travail d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles
Profitez d’un média expert et unique
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vousLe 24/07/2024 à 19h55
Le 24/07/2024 à 20h24
Modifié le 24/07/2024 à 21h45
Yann Lecun parle aussi du DSA/DMA, publié il y a un an et demi