NVIDIA annonce son GPU Blackwell (B200) pour l’IA, jusqu’à 20 000 TFLOPS (FP4)
Bientôt une vitesse infinie en FP0 ^^
 pour l’IA, jusqu’à 20 000 TFLOPS (FP4)")
Comme prévu, NVIDIA a profité de sa conférence GTC pour annoncer sa nouvelle architecture GPU pensée pour l’intelligence artificielle. Nom de code Blackwell, en hommage à David Blackwell, « le premier afro-américain à être membre de la National Academy of Sciences » rappelle Wikipédia.
Blackwell (B200) succède donc à Hopper (H100), largement utilisée pour l’intelligence artificielle, notamment générative. Autant dire que Blackwell était donc attendue au tournant. L’IA permet d’ailleurs à NVIDIA de publier d’excellents chiffres sur son bilan comptable avec 22 milliards de dollars de revenus sur sa dernière année fiscale, pour 12,3 milliards de dollars de bénéfices net. Depuis le début de l’année, l’action a grimpé de plus de 80 %.
208 milliards de transistors… enfin 2x 104 milliards plus exactement
NVIDIA a sorti l’artillerie lourde sur les chiffres, même s’il faut parfois lire entre les lignes. La puce intègre la bagatelle de 208 milliards de transistors, contre 80 milliards pour H100 et 54 milliards pour A100. NVIDIA n’annonce pas de gros changement sur la finesse de gravure avec le process 4NP de TSMC au lieu du 4N.
La société utilise une « astuce » et ne s’en cache pas : son GPU Blackwell (B100) est un assemblage de deux dies avec « une interconnexion puce à puce de 10 téraoctets par seconde (To/s) dans un unique GPU unifié ». Un peu à la manière des premiers CPU avec deux cœurs, il s’agit d’assembler deux GPU sur un même die, permettant ainsi de doubler les performances.
On ne passe donc pas réellement de 80 à 208 milliards de transistors par GPU, mais de 80 à 104 milliards sur une base comparable, soit 30 % de plus tout de même avec la même finesse de gravure. On était à 50 % de plus entre A100 (gravé en 7 nm par TSMC) et H100 (4N par TSMC). NVIDIA ne donne pas la superficie de sa puce B200, impossible donc en l’état de connaitre la densité.

Transformer Engine de seconde génération avec FP4
Le nouveau GPU passe au Transformer Engine de seconde génération, un accélérateur introduit dans Hopper et qui a porté ses fruits. Pour rappel, grâce à cette technologie, les Tensor Core de Hopper « ont la capacité d’exploiter des formats de précision mixtes FP8 et FP16 afin d’accélérer de manière significative les calculs d’IA pour les transformateurs ». Plus on baisse la précision, plus la vitesse de traitement est élevée, c’est mathématique.
Avec Blackwell, NVIDIA descend encore plus bas avec FP6 et même FP4. « Cela double les performances et la taille des modèles de nouvelle génération que la mémoire peut prendre en charge, tout en conservant une grande précision », affirme NVIDIA. À confirmer lors des tests quand le GPU sera disponible.
Nous avons pour rappel déjà consacré un dossier au fonctionnement des virgules flottantes (FP, Floating Point) dans le monde de l’informatique. À (re)lire pour bien comprendre ce qu’est le FP4, FP8, FP16 et les enjeux de précision.
Jusqu’à 20 000 TFLOPS, mais il faut détailler les calculs
Sur scène, Jensen Huang (CEO et cofondateur de NVIDIA) annonce fièrement des performances très élevées avec pas moins de 20 000 TFLOPS (ou 20 PFLOPS), mais en FP4.
Le graphique ci-dessous compare Blackwell (B200) à Hopper (H100) et Ampere (A100), mais en mélangeant quelque peu les torchons et les serviettes. Il est indiqué 4 000 TFLOPS pour H100 en FP8 et 620 TFLOPS en BF16/FP16 pour A100. Certes H100 ne fait pas de FP4 et A100 de FP8, mais tout le monde fait du FP16, par exemple.
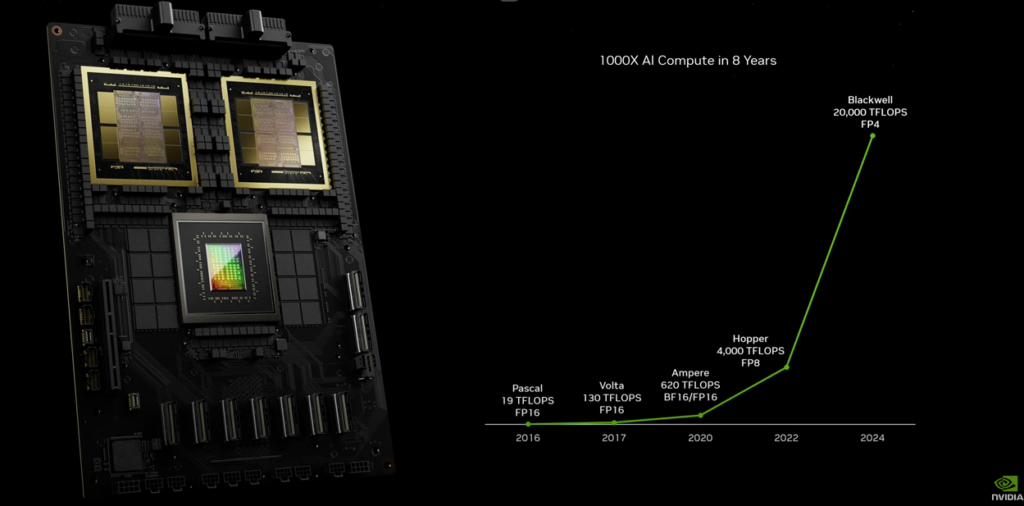
Pour avoir une base comparable, on pourrait ainsi mettre Blackwell en face de ces prédécesseurs avec une puissance de 10 000 TFLOPS en FP8 ou 5 000 TFLOPS en FP16 (respectivement 2x et 4x moins qu’en FP4). Rappelons également que la B200 est composée de deux GPU sur une même puce, contre un seul pour les générations précédentes.
25 % de mieux entre un unique GPU Hopper et Blackwell
Un unique GPU Blackwell a ainsi une puissance de 5 000 TFLOPS en FP8 et de 2 500 TFLOPS en FP16, quand H100 est à 3 958 TFLOPS en FP8 et 1 979 TFLOPS en FP16. On descend à 624 TFLOPS sur A100 en FP16.
Il y a donc bien une hausse des performances sur le seul GPU avec le passage à Blackwell : on grimpe de 3 958 à 5 000 TFLOPS en FP8, soit un peu plus de 25 %. NVIDIA double la mise avec deux GPU sur une seule puce. Le prix de Blackwell n'est en revanche pas connu.

192 (2x 96) Go de HBM3E
Quoi qu’il en soit, Blackwell dispose de 192 Go de mémoire HBM3E, contre 141 Go pour H200 (Hopper en version HBM3E) et 80 Go de HBM3 pour la version H100 de Hopper. La bande passante de la mémoire est de 8 To/s, contre 4,8 To/s pour le H200.
NVLink 5e génération, jusqu’à 576 GPU ensemble
NVIDIA annonce au passage la 5e génération de NVLink, avec 1,8 To/s de bande passante, le double de la génération précédente. La société indique qu’il est possible de relier jusqu’à 576 GPU.
NVIDIA met en avant d’autres technologies sur son nouveau GPU, notamment Secure IA, Decompression Engine ainsi que le Reliability, Availability, and Serviceability (RAS) Engine.

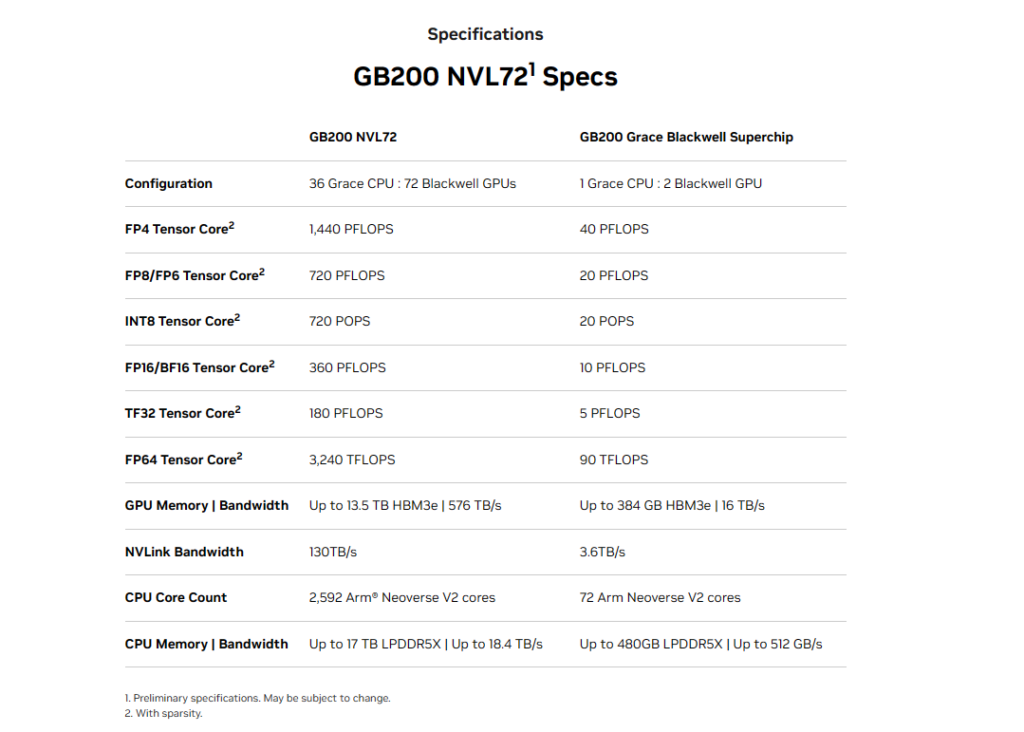
GB200 Grace Blackwell Superchip, NVL36 et NVL72
Comme avec la génération précédente, NVIDIA propose diverses combinaisons de son GPU. Commençons par le GB200 Grace Blackwell Superchip.
Comme avec le GH200 (Grace Hopper Superchip), il s’agit de mélanger un CPU « Grace » de NVIDIA avec 72 cœurs Arm Neoverse V2 et deux GPU Blackwell (chacun comportant deux puces, dont quatre GPU, vous suivez ?).

Un Compute Node comprend un double système GB200 – et donc 2x CPU Grace et 4x GPU B200 (chacun avec deux puces) – avec un système de refroidissement liquide. NVIDIA empile jusqu’à 18 Compute Node pour former des configurations GB200 NVL36 et NVL72.
On y retrouve donc 18 fois (NV36) et 36 fois (NV72) plus de CPU et GPU que dans le GB200, le tout relié via un NVLink Switch. On passe respectivement à 18/36 CPU Grace et 36/72 GPU Blackwell… avec des performances théoriques multipliées par 18 ou 36.
De quoi permettre à NVIDIA d’annoncer plus de 1 400 PFLOPS en FP4 (ou 1,4 EFLOPS, avec un E pour Exa) sur le système GB200 NVL72, excusez du peu.
On termine enfin avec le NVIDIA DGX SuperPOD avec des DGX GB200, une « infrastructure d’IA rackable à refroidissement liquide pouvant accueillir des milliers de puces NVIDIA GB200 Grace Blackwell Superchip ».
NVIDIA annonce que son nouveau DGX SuperPOD permet de monter « jusqu’à 11,5 EFLOPS pour l’IA avec une précision FP4, et 240 téraoctets de mémoire ».

En guise de conclusion, Jensen Huang affirme que, grâce aux performances de Blackwell (et notamment le passage au FP4), « la quantité d'énergie que nous économisons, la bande passante réseau que nous économisons et la quantité de temps perdu que nous économisons seront énormes ».
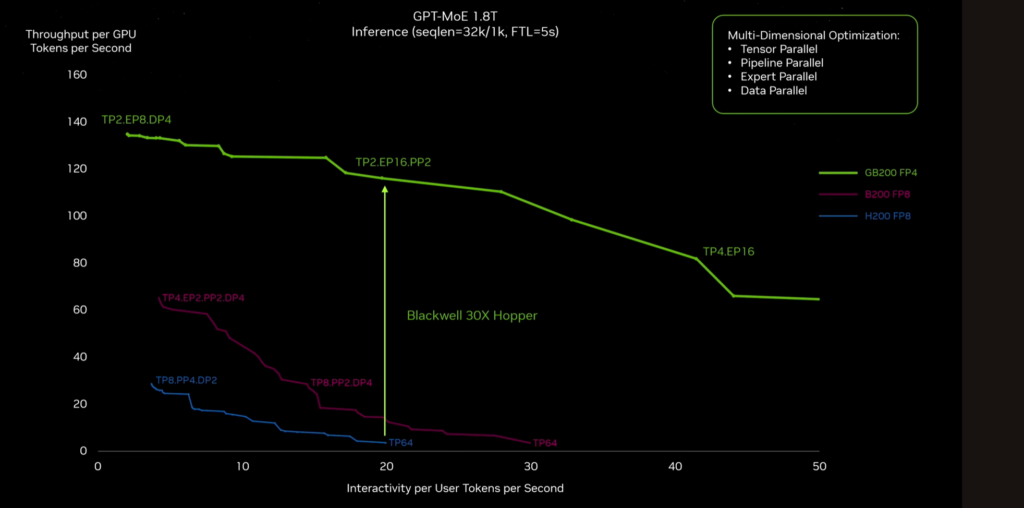
Plus de TFLOPS veut dire un temps de traitement réduit pour les intelligences artificielles. « L'architecture Blackwell offre une accélération 30 fois supérieure à la génération précédente NVIDIA Hopper pour les modèles massifs tels que le GPT-MoE-1.8T » (MoE pour Mixture of Experts avec 1,8 milliard de paramètres), affirme le fabricant.

Commentaires (17)
Le 19/03/2024 à 13h31
Alors d'accord ça va faire moins rêver et de plus l'IA est devenu le principal moteur de vente sur ces puces, mais nous autres clients qui utilisons leur GPU pour du compute depuis presque 15 ans nous sentons un peu trahis 🫤
Le 19/03/2024 à 14h32
Donc ils tournent leur discours pour attirer de nouveaux marchés.
Le 19/03/2024 à 14h40
Le 19/03/2024 à 21h32
Le premier GPU spécifiquement fait pour le GPU computing était le GP100 (architecture Pascal), qui se distinguait des GP102/104 qui GPU orienté graphique par la mémoire HBM2 et surtout par le support du FP64 à la moitié de la vitesse du FP32, alors que la vitesse du FP64 sur les GPU grand publique est divisé par 32 par rapport au FP32. C'est cette perfo en FP64 qu'on cherchait en achetant ces GPU.
Même après le virage vers l'IA, ces GPUs orienté computing ont toujours gardé ce support à demi vitesse du FP64, sur les GV100, A100, et H100. Je suppose que c'est toujours le cas sur le nouveau GB100, mais ce n'est pas encore clairement annoncé.
Mais vince120 a raison, nous on est "acquis", faute de concurrence malheureusement et ils préfèrent faire la danse du ventre devant les data scientists qui sont en pleine croissance.
Modifié le 20/03/2024 à 15h07
J'en viens à envisager de tester des codes de benchs pour quelques heures sur des offres de cloud computing (pour ne pas me tromper dans l'achat), mais c'est dur à trouver et encore assez cher.
Là je dois renouveler un serveur, et je ne sais pas comment comparer les perfs FP32/64 entre les V100, les RTX A6000 Ampere, les RTX 6000 Ada, et les H100.
Le 20/03/2024 à 16h41
Le 20/03/2024 à 21h56
Pour ma part quand je dois faire cette exercice, je mesure les FLOPS de mon code et je calcule le FLOPS_de_mon_code/FLOPS_theorique, ayant pris soin de vérifier que j'arrive à retrouver les FLOPS_theoriques (typiquement, je trouve ~99% des perfs théoriques). De là, je me sers de ce ratio pour le multiplier par les perfs théoriques du constructeur pour un autre modèle pour estimer les FLOPS que je vais disposer pour mon code, et de la estimer le temps.
Ce n'est pas parfait comme méthode. Elle a des limitations et fait des hypothèses mais en pratique, l'ordre de grandeur est correct.
Pour l'aspect mémoire (quand la limitation est plus memory bound), j'utilise le throughput (GB/s) dont je calcule un ratio par rapport aux perfs théoriques. Les limitations sont les même qu'au-dessous. A noter, qu'avec la mémoire, l'ordre de grandeur est parfois moins fiable qu'avec le FLOP.
Mes deux cents.
Le 20/03/2024 à 23h44
Et sur cuFFT je suis plutôt à 30/40%.
Le 21/03/2024 à 11h38
La multiplication de matrice peut difficilement atteindre les perfs max. à cause du besoin de transposition d'une des matrices pour le produit, et d'accès mémoires plus coûteux. C'est pourquoi je préfère bêtement faire un produit scalaire sur des vecteurs à n-dimensions car, en dehors du chargement mémoire (mais le prefetcher sont redoutables), le FLOPS est uniquement du FMA. Mais je maintiens qu'il ne s'agit que d'un test pour vérifier les perfs annoncés par le constructeur. En pratique, ce test ne représente pas la réalité ou l'usage commun (éventuellement en IA mais j'en doute).
Les algos de FFT sont plus basées sur de la permutation de lanes SIMD que du FMA. La mesure en FLOPS est moins pertinente pour ces algorithmes, mais pas dénué d’intérêt.
LINPACK mesure les perfs sur un type de calculs très commun dans les milieux scientifiques et industrielles ( de mémoire, c'est de l'inversion de matrice dense). Le but de LINPACK est d'être représentatif des calculs les plus utilisées, pas de chercher à atteindre les perf max. vendus par le constructeur. C'est plutôt le rôle de ce "bête" benchmark c = vec{a} \dot \vec{b} de vérifier ceci.
Le 21/03/2024 à 13h13
Ce qui va dans ce sens c'est que j'obtiens plus ou moins les même performances avec ce code qui fait de la multiplication sans transpo, donc comme pleins de produits scalaires :
Si tu as plus optimal, je suis preneur 🙂
Le 21/03/2024 à 21h21
Je vais réessayer de reproduire le code dont je parle pour le DP. Si j'y arrive, je te MP.
Concernant le code que tu montres, je peux au mieux te donner deux pistes à explorer:
1. Les conditions dans la boucle for, c'est une mauvais pour les GPU. Ces petites bêtes ne sont pas très bien équipées pour ce qui touche à l’exécution spéculative. L'écrire de manière "branchless" serait plus pratique pour le GPU et plus dans son fonctionnement (SIMD).
2. A la ligne 54, tu as des accès non-contigüe entre tes deux matrices sa & sb. Le GPU n'est pas super friand de ça (encore une fois en raison de sa façon de fonctionner). Note que le même problème existe avec les CPU.
Le 20/03/2024 à 23h41
Le 21/03/2024 à 16h49
L'effet de bord c'est ce que tu dis : le ratio performance FP64/prix du GPU est de moins en moins bon.
Le 19/03/2024 à 16h34
(qui coûteront certes le prix d'une voiture moyenne
Le 19/03/2024 à 19h07
Hé ben, j'ai peur du traitement du reste des informations. 😅
Ok, il n'était peut-être pas spécialiste du domaine, mais t'avait des erreurs.
Et des raccourcis énormes.
Le 19/03/2024 à 19h54
Le 19/03/2024 à 21h19
On comprend tout de suite mieux pourquoi le graphique mélange les unités afin de fabriquer de toutes pièces l'exponentielle : la réalité est bien plus tristoune, derrière le H100. Mais il faut vendre.
On comprend par-là même le doublement du processeur.
Et par le doublement du processeur, on comprend aussi que le prix va piquer.
Tout est dit, dans les non-dits : Ça pigeonne sec.