

Elsevier récupère le plus de données possible sur les étudiants et chercheurs américains
« Pour le bien-être de l’humanité »

L’association américaine Sparc a analysé les pratiques de l’éditeur scientifique Elsevier sur ses outils numériques utilisés dans les universités et institutions de recherche américains pour consulter les articles scientifiques. Elle signale la collecte de nombreuses données par cette entreprise devenue filiale d’un des plus grands data brokers (courtiers de données).
Dans une étude mise en ligne début novembre, l’association américaine de bibliothécaires universitaires SPARC (Scholarly Publishing and Academic Resources Coalition) analyse les outils utilisés par Elsevier pour recueillir des données sur les utilisateurs de ScienceDirect.
Cette plateforme est la porte d’entrée pour accéder à toutes les revues scientifiques détenues par l’éditeur. Celui-ci a, depuis quelques années, participé activement à la concentration du marché de l’édition scientifique en achetant de nombreuses revues. En 2020, Elsevier représentait 16 % du marché et possédait plus de 3 000 revues scientifiques.
Elsevier, un data broker de l’activité scientifique
Mais l'entreprise s'est aussi transformée et son activité d'édition n'est plus vraiment au centre de ses préoccupations. Sur son site internet en 2020, Elsevier ne se présentait plus comme un éditeur, mais comme une « entreprise d’analyse de données qui aide les institutions, les professionnels de santé et des sciences à améliorer leurs performances pour le bien-être de l’humanité ». L'entreprise a encore changé sa page de présentation.
Maintenant, celle-ci indique : « nous fournissons des analyses de données sophistiquées qui aident nos clients à prendre des décisions majeures et à atteindre leurs objectifs stratégiques, en combinant de vastes ensembles de données provenant de sources de contenu structurées et non structurées. Notre plateforme de big data compte plus de 1,2 milliard de points de données uniques, dont des millions d’auteurs, d’institutions, de dossiers de publications, de brevets, de médicaments, de subventions et de documents de politiques ». Bref, Elsevier est devenu un data broker de l'activité scientifique.
L'association précise bien que son étude « reflète les informations publiquement disponibles au moment de l'examen (de l'été 2022 à l'été 2023) et se concentre sur le contexte nord-américain ». Et, en effet, le RGPD en place en Europe impose des restrictions plus importantes à Elsevier que la législation américaine. Il n'est donc pas question ici de transposer les pratiques de l'entreprise aux États-Unis dans notre contexte, mais d'informer sur ce qu'elle fait lorsque la législation lui laisse les coudées plus franches. Sparc ajoute d'ailleurs que son étude n'est pas une analyse du respect ou non des lois sur la protection des données par ScienceDirect.
Par contre, l'association explique que « d'après nos conclusions, de nombreuses pratiques de ScienceDirect en matière de confidentialité des données sont en contradiction directe avec les normes et les lignes directrices des bibliothèques en matière de confidentialité. Les pratiques en matière de confidentialité des données identifiées dans notre analyse sont semblables à celles que l'on trouve dans de nombreuses entreprises et organisations qui suivent et collectent les données des utilisateurs pour maintenir des modèles commerciaux axés sur les données et intrusifs ».
Des pratiques de suivi dignes des régies publicitaires
L'association fait une liste d'exemples de pratiques utilisées par ScienceDirect qu'elle a pu constater :
-
- Utilisation de balises web (ou pixels espions), de cookies et d'autres méthodes invasives de surveillance du web pour suivre le comportement de l'utilisateur en dehors du site web de ScienceDirect,
-
- Collecte extensive d'un large éventail de données personnelles (par exemple, données comportementales et de localisation) à partir de ScienceDirect, combinées à des données personnelles recueillies auprès de sources autres que ScienceDirect (c'est-à-dire des tiers à l'intérieur et à l'extérieur de RELX et des courtiers en données, comme indiqué dans la politique de confidentialité d'Elsevier et l'avis de confidentialité des consommateurs américains),
-
- Collecte de données personnelles par des tiers, y compris des moteurs de recherche, des plateformes de médias sociaux et d'autres agrégateurs de données personnelles et profileurs tels que Google, Adobe, Cloudflare et New Relic, par le biais d'une utilisation intensive de traqueurs tiers sur le site de ScienceDirect,
-
- Divulgation de données personnelles à d'autres produits Elsevier et possibilité de divulguer des données personnelles à d'autres unités commerciales au sein de RELX, y compris les produits et services à risque vendus aux entreprises, aux gouvernements et aux organismes chargés de l'application de la loi,
-
- Traitement et divulgation de données à caractère personnel (et de données à caractère personnel déduites d'autres) à des fins de publicité et de marketing ciblés et personnalisés.
Sparc a pu s'apercevoir de toutes ces pratiques en analysant les cinq pages suivantes de la plateforme :
-
- La page d'accueil (https://www.sciencedirect.com)
-
- Le portail d'accès aux revues et livres de l'éditeur (https://www.sciencedirect.com/browse/journals-and-books)
-
- La page du moteur de recherche (https://www.sciencedirect.com/search?qs=cat%20behavior)
-
- La page d'un article en accès ouvert (https://www.sciencedirect.com/science/article/pii/S016815912200020X)
-
- Et la page d'identification (https://id.elsevier.com)
L'association a utilisé sept outils classiques quand il s'agit de connaître (et bloquer) d'éventuels traqueurs sur le web : Website Evidence Collector, Blacklight, NoScript, uBlock Origin et les outils de développement des navigateurs Firefox et Chrome.
Le portail utilise notamment des cookies persistants avec, pour certains, des dates d'expiration allant jusqu'à 50 ans après la première navigation. Sparc a aussi relevé l'utilisation d'images "single pixel" permettant de suivre le comportement des utilisateurs.
Elle a observé que certains cookies et pixels espions, « qui semblent provenir des noms de domaine sciencedirect.com ou elsevier.com, redirigent vers des domaines tiers ». Comme Sparc l'explique, « il s'agit d'une pratique courante sur d'autres marchés qui consiste à placer des traceurs tiers pour la publicité et les données d'analyses, en dissimulant aux utilisateurs l'étendue de la collecte des données et du partage à des plateformes tierces. Un exemple est smetrics.elsevier.com qui redirige vers elsevier.com.ssl.d1.sc.omtrdc.net. Le domaine omtrdc.net est lié à Adobe Experience Cloud, une suite intégrée de produits de marketing, d'analyse web et de courtage de données basée sur le cloud ».
Sparc a pu s'apercevoir que, même sans être connecté, le portail collecte des données personnelles dont l'adresse IP et des informations sur le navigateur et l'appareil utilisé. « Les cookies et balises peuvent contenir des identifiants pseudonymisés attachés aux données personnelles collectées » explique-t-elle. Elle ajoute que le blocage du JavaScript, qui permet de se prémunir contre la récupération des données, casse les fonctionnalités simples du site comme la recherche et le téléchargement d'articles en « accès ouvert ».
Un « réseau bordélique de documentation »
Selon Sparc, il est classique que les contrats et licences de plateformes possèdent peu d'informations sur la confidentialité des données des utilisateurs et que ScienceDirect ne fait pas exception, ayant une seule sous-section dédiée à ce sujet.
L'association a donc épluché les documents d'information sur la collecte de données personnelles fournis en ligne par le portail. Elle s'est sentie obligée de proposer un schéma pour représenter le « réseau (bordélique) de distribution des informations sur la confidentialité des données », ci-dessous :
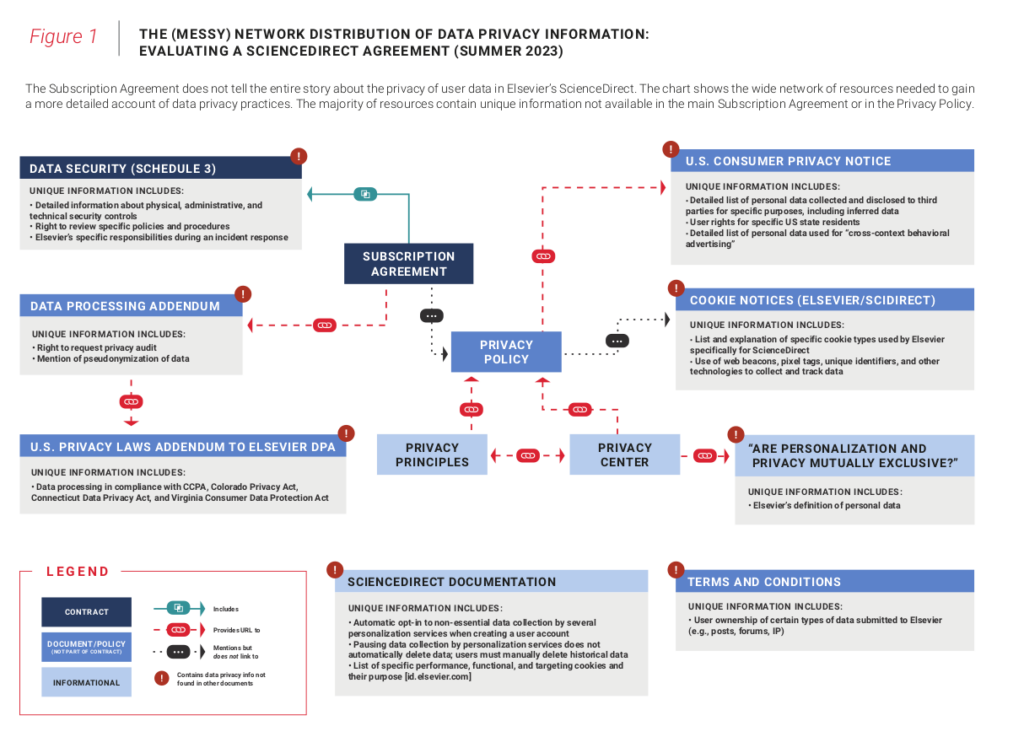
Avec toute cette documentation, Sparc a trouvé par exemple dans la « U.S. Consumer Privacy Notice » qu'Elsevier « a collecté et divulgué des types spécifiques d'informations personnelles, telles que :
-
- Les informations relatives à l'activité sur Internet ou sur d'autres réseaux électroniques, telles que l'historique de navigation, l'historique de recherche, le comportement en ligne, les données d'intérêt et les interactions avec nos sites Web et d'autres sites Web, applications, systèmes et publicités,
-
- Les données de géolocalisation, telles que l'emplacement approximatif de l'appareil,
-
- Les inférences tirées des informations personnelles énumérées ci-dessus pour créer un profil ou un résumé concernant, par exemple, les préférences et les caractéristiques d'un consommateur,
-
- Les informations personnelles sensibles, telles que celles qui révèlent le numéro de passeport d'un consommateur, son origine raciale ou ethnique, son identifiant et son mot de passe ».
Impensable dans une bibliothèque physique
L'association se rend bien compte qu'Elsevier n'est qu'un exemple parmi les nombreuses entreprises qui « qui placent des informations détaillées sur la collecte, le traitement et la divulgation des données dans des avis supplémentaires distincts de la politique principale de protection de la vie privée, afin de se conformer aux lois spécifiques des États américains ».
Mais Sparc explique que « le suivi des utilisateurs, qui serait impensable dans une bibliothèque physique, se fait désormais de manière routinière par le biais de ces plateformes. L'intégration potentielle de ce suivi à d'autres secteurs d'activité, y compris les outils d'analyse de la recherche et les services de courtage de données, soulève des questions pressantes pour les utilisateurs et les institutions ».

Commentaires (4)
Le 15/12/2023 à 00h26
Le 15/12/2023 à 01h06
J'imagine que ResearchGate est du même niveau.
Je n'ai pas compris exactement ce qu'ils proposaient avec ces données par contre. Quelqu'un aurait un exemple à me proposer ?
Le 15/12/2023 à 12h22
(genre, on rachète un outil "top moumoute", pour lui ajouter des espions dans tous les sens)
Modifié le 28/12/2023 à 18h28
Mais l'utilisation d'un VPN et d'un bloqueur de publicité coupe court à ce genre de pratiques, non ? Gémir est inutile. Boycotter est futile. Je vote pour l'adaptation.
Signaler un commentaire
Voulez-vous vraiment signaler ce commentaire ?