Alors que Meta a annoncé son modèle « frontière » Llama 3.1 mardi 23 juillet, Mistral sort de son côté la version 2 de son modèle Large.
Pour montrer les performances de la nouvelle version de son plus important modèle de langage qui a trois fois moins de paramètres que Llama 3.1, Mistral met en avant les comparaisons d'utilisation de Large 2 concernant la génération de code :
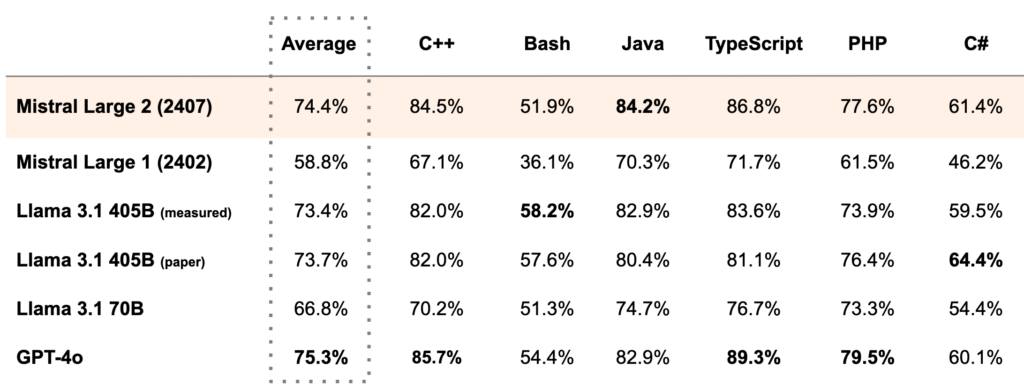
L'entreprise sort la nouvelle version de son modèle dans les mêmes conditions que la version précédente : une licence permettant de l'utiliser pour de la recherche et des usages non commerciaux et l'obligation d'un accord avec elle en cas de projet commercial.
L'entreprise vante les performances de son modèle concernant le multilinguisme : « Il excelle notamment en anglais, français, allemand, espagnol, italien, portugais, néerlandais, russe, chinois, japonais, coréen, arabe et hindi », affirme-t-elle.
Mistral livre aussi des comparaisons flatteuses pour son modèle à ce sujet :
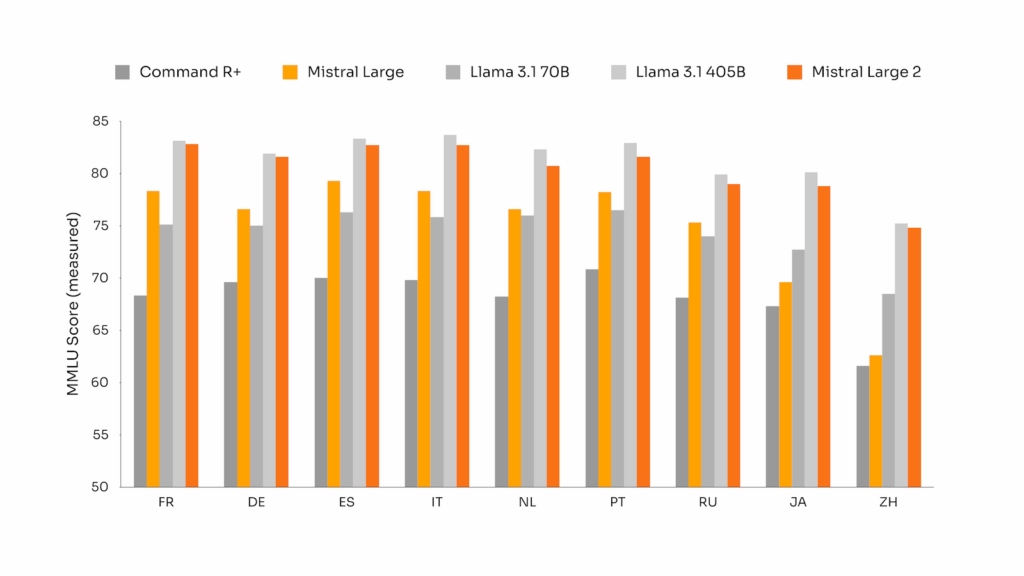
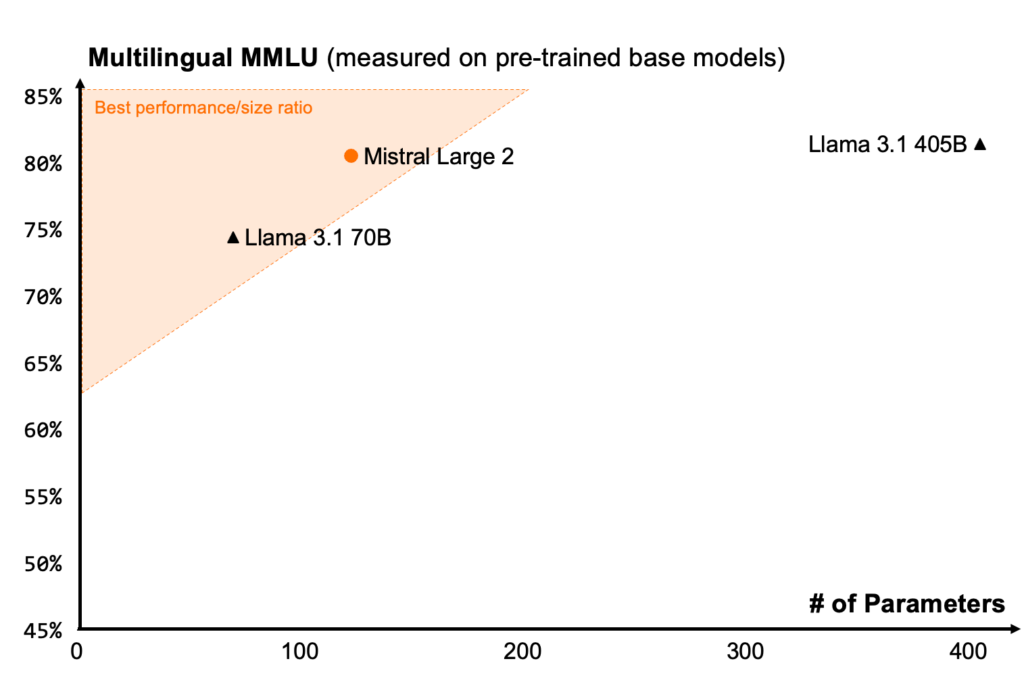
Mais Mistral ne communique que très peu d'autres informations concernant son modèle, comparé, par exemple, avec ce que peut faire Meta à propos de Llama 3.1, qui n'est pourtant pas si ouvert que ça.
Large 2 est déjà disponible sur les plateformes de cloud computing Google Vertex AI, Azure AI Studio, Amazon Bedrock et IBM watsonx.ai.
Commentaires (9)
Vous devez être abonné pour pouvoir commenter.
Déjà abonné ? Se connecter
Abonnez-vousLe 25/07/2024 à 10h25
Le 25/07/2024 à 11h25
Le 25/07/2024 à 11h43
C'est quand même pas brillant comme résultat (tout système confondu). 75 % de moyenne au maximum.
Donc, ceci a peu de sens. En effet, on compare des résultats dans un domaine très spécialisé (la génération de code) en mettant en avant la quantité de paramètres (tout domaine confondu) que comprennent les modèles. Rien ne dit que le nombre de paramètres servant à la génération de code ait le même rapport de 3 entre les modèles.
Le 25/07/2024 à 12h25
Sinon, si tu regardes bien les scores, ce qui plombe le plus c'est principalement Bash puis C# et une moindre mesure PHP.
Pour bash, il fait toujours mieux que moi.
Le 25/07/2024 à 16h38
Le 25/07/2024 à 16h40
Ma démarche: je comprends pas grand chose au systeme de classement des modèles, notamment sur huggingface.
J'ai donc essayé d'en télécharger un bien noté "au pif" avec LMStudio et lui demander de m'expliquer.
Bha c'est pas très claire et à une question posée en francais il répond une fois sur deux en anglais.
Après il faudrait que mon PC est les ressource suffisante pour le faire fonctionner.
Modifié le 25/07/2024 à 17h31
EDIT : lien vers le modèle sur le site d'Ollama --> https://www.ollama.com/library/mistral-large
Le 25/07/2024 à 20h10
Pour le matos, nop pas vraiment, GTX 1080 et 16GO de RAM.
Mais ca permets de faire fonctionner certains des modèles.
Le "jeux" de cette après midi, demander de générer une fonction bash permettant de générer un pod Kubernetes de test. Ca fonctionne pas trop mal, mais il faut demander de corriger certaines erreurs (EOF non fermé par exemple)
Le 26/07/2024 à 09h24
Les 24GB de VRAM et les 64GB de RAM étaient pleins. En même temps, le modèle seul pèse 63GB !