Graphcore Bow : 3D stacking, prix inchangé mais plus d’efficacité
Cette fois, c'est la bonne ?

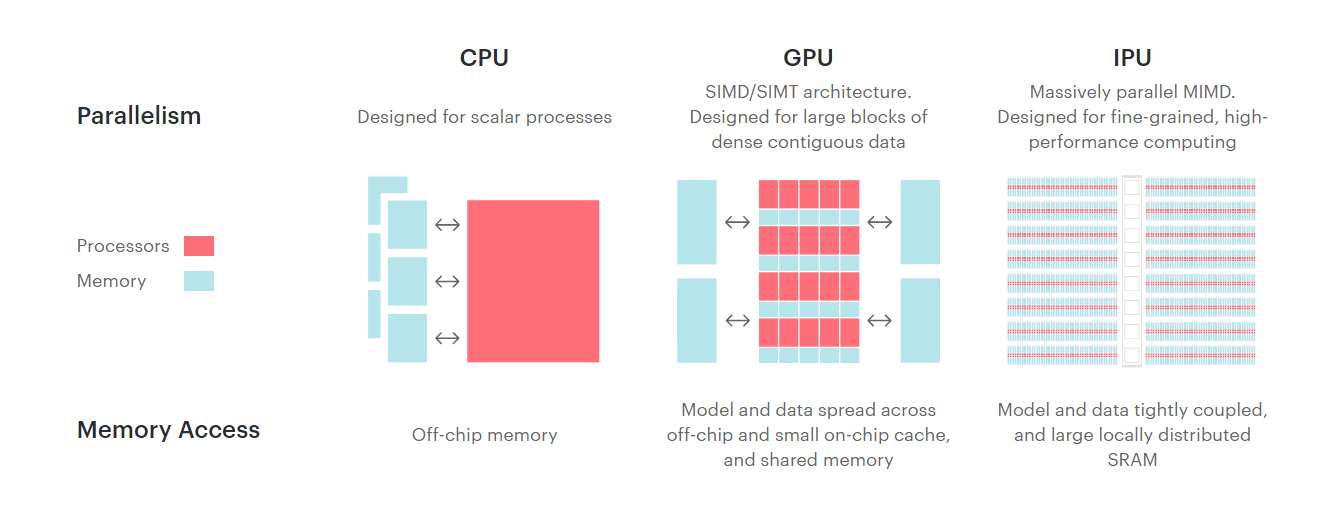
Alors que les géants du GPU rivalisent d'ingéniosité pour faire de leurs puces de véritables monstres des calculs modernes, notamment dans le domaine de l'intelligence artificielle, d'autres ont fait le choix de produire des processeurs spécialisés, comme le Britannique Graphcore. Il présente sa troisième génération.
Il y a quelques années, Graphcore se lançait sur le marché prometteur des puces de calcul spécialisées dans l'IA avec ses IPU (Intelligence Processing Unit). Ces dernières sont proposées sous la forme de serveurs mais aussi de racks presque clé en main, certains fournisseurs de service cloud (CSP) étant déjà partenaires de l'initiative.
L'entreprise, basée à Bristol et née de la rencontre de Nigel Toon et Simon Knowles il y a 10 ans, vient de lancer sa troisième génération : Bow. Malgré un prix inchangé, elle est jusqu'à 40 % plus performante, 16 % plus efficace d'un point de vue énergétique et utilise un procédé lorgné par de grands constructeurs : le 3D stacking (SoIC-WoW).
Mais si Graphcore compte déjà plusieurs alliés, notamment sur le marché français, elle doit encore convaincre.
Trois générations d'IPU : l'heure de la maturité ?
Car qui dit puce spécialisée dit... développement spécifique. Et c'est ce qui freine la plupart des acteurs sur de telles solutions pour le moment. Elles se destinent ainsi principalement à ceux qui peuvent investir massivement dans du code maison, taillé pour une seule et même architecture, notamment dans le calcul haute performance (HPC).
SiPearl, qui réalise le processeur des prochains supercalculateurs européen, ainsi qu'Atos travaillent ainsi avec GraphCore. Mais l'entreprise n'en reste pas moins proche des startups, nous disant travailler avec Hugging Face, une jeune pousse française qui a créé un véritable « GitHub du machine learning ».
Cette génération est, comme la précédente, proposée sur la forme de serveurs 1U Bow-2000 et de « POD » pouvant aller jusqu'à 1024 IPU. Chaque puce se compose de 1 472 cœurs de calcul, 900 Mo de mémoire embarquée (65 To/s), 10 liens à 320 Go/s servent aux différentes interconnexions. La performance annoncée est de 350 TFLOPS d'AI Compute (soit 1,4 PFLOPS par serveur), sans que l'on sache exactement à quoi cela correspond.










Pour être plus concrète, l'entreprise évoque un entrainement 5x plus rapide sur un BOW POD16 à 150 000 dollars que sur un DGX A100 de NVIDIA qui en coûte le double sur l'entrainement d'Efficientnet-B4. Mais surtout un gain de 29 % à 39 % sur différents modèles, avec une amélioration de 9 % à 16 % en performance/watt. Nous n'en saurons pas plus, notamment sur la consommation de chaque puce, serveur et POD.
Cap sur les supercalculateurs et centres de recherche
L'équipe indique que la bonne « scalabilité » de ses solutions est toujours au rendez-vous, ce, sans la moindre évolution nécessaire du code, toujours via son Poplar SDK. Elle dit d'ailleurs se diriger vers le « Good » Computer (en référence à Irving John Good) qui serait capable de proposer une puissance de calcul de 10 ExaFLOPS (en « AI Floating point ») avec 8 192 de ses IPU. Coût de la bête 120 millions de dollars.
D'ici là, elle explorera de nouvelles pistes en partenariat avec le Pacific Northwest National Laboratory (PNNL) du département de l'énergie américain dans la chimie et la cybersécurité.



Commentaires (1)
Vous devez être abonné pour pouvoir commenter.
Déjà abonné ? Se connecter
Abonnez-vousLe 07/03/2022 à 10h13
Clever cloud, ceux du podcast vidéo “Message à caractère informatique”, passionnant, à partager.
Sinon, pour les puces IA, l’écosystème se met en place, et la transition s’opère depuis la simulation logicielle pure vers les puces dédiées, scalables, et énergétiquement plus efficaces que les GPU massifs que l’on connaît.