Apple soulève un peu le capot de ses modèles utilisés par Apple Intelligence
L'IA et dans la Pomme

Si Apple a sorti récemment sa famille de modèles de langage DCLM de façon très ouverte, ce n'est pas le cas de ses modèles de fondation utilisés par Apple Intelligence. La WWDC passée, l'entreprise communique un peu plus sur les spécificités techniques de ces modèles.
Apple avait publié le 10 juin un communiqué décrivant ses modèles de fondation tournant sur serveur et sur ses appareils, mais sans donner beaucoup d'informations.
Un mois et demi après, les chercheurs de l'entreprise ont voulu entrer un peu plus dans les détails. La firme a mis en ligne un « papier » dans un premier temps sur ses propres serveurs, puis l'a déposé sur le serveur de prépublication scientifique arXiv (.PDF).
Des modèles spécialisés
Pas non plus de publication sur Hugging Face pour les modèles ni pour les données d'entrainement. Mais le fichier pdf contient quand même de nombreuses informations sur l'architecture mise en place par Apple et sur les modèles de l'entreprise. Ce texte permet aussi de comprendre un peu ce que l'entreprise met derrière le terme « Apple Intelligence ».
Les chercheurs expliquent qu' « Apple Intelligence se compose de plusieurs modèles génératifs très performants qui sont rapides, efficaces, spécialisés dans les tâches quotidiennes de nos utilisateurs et qui peuvent s'adapter à la volée à leur activité en cours ».
L'entreprise a simplement nommé ces modèles les « Apple Foundation Models », ou AFM. Ce rapport présente de façon plus détaillée deux de ces modèles : AFM-on-device et AFM-server qui, comme leurs noms l'indiquent, sont créés pour tourner respectivement sur les appareils et sur les serveurs d'Apple.
AFM-on-device est un modèle d'environ 3 milliards de paramètres. Toutefois, Apple ne précise pas le nombre de paramètres de son modèle tournant sur ses serveurs, se contentant de le qualifier de « plus grand ».
Chaque modèle d'Apple Intelligence est affiné pour certaines tâches comme l'écriture, l'affinage d'un texte, la priorisation ou le résumé des notifications, la création d'images pour des conversations en famille ou avec des amis, ou encore la proposition d'actions in-app pour simplifier les interactions entre les applications.
Apple Intelligence, une architecture basée sur plusieurs modèles
Les chercheurs d'Apple ont constaté que les petits modèles affinés pour des tâches spécifiques atteignent des niveaux inégalés. « Bien que nous ayons atteint des niveaux impressionnants de capacité générale dans notre modèle de base, la mesure réelle de sa qualité est la façon dont il fonctionne pour des tâches spécifiques dans nos systèmes d'exploitation » expliquent-ils.
Ils ajoutent qu'ils ont « développé une architecture [en schéma ci-dessous], basée sur des adaptateurs remplaçables en cours d'exécution, pour permettre au modèle de base unique d'être spécialisé pour des douzaines de tâches de ce type ».
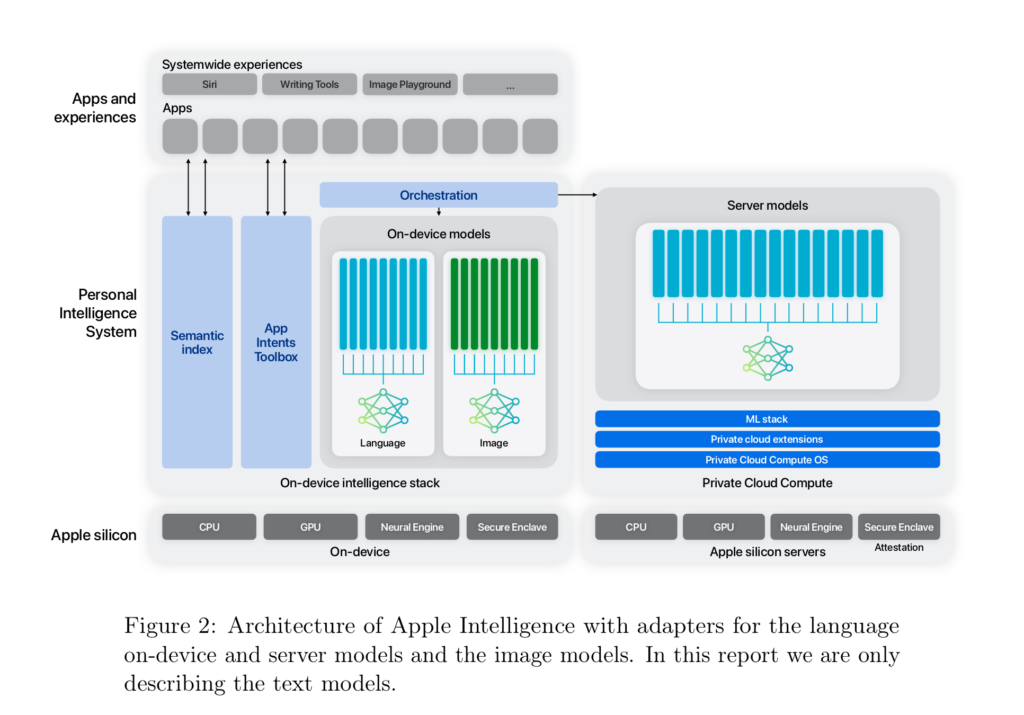
Quelques détails sur les données d'entrainement
Les chercheurs d'Apple affirment que leur jeu de données utilisé pour entrainer leurs modèles inclut des données dont les droits sont détenus par des éditeurs, des jeux de données présélectionnés « disponibles » ou « en libre accès », ainsi que d'informations accessibles publiquement sur le web et indexées par le bot Applebot.
« Étant donné l'importance que nous accordons à la protection de la vie privée des utilisateurs, nous notons qu'aucune donnée privée des utilisateurs d'Apple n'est incluse dans le mélange de données », affirment les chercheurs de l'entreprise.
Ont-ils utilisé des données dont ils n’ont pas les droits ? Aucune information sur ce point. Ils ne réfutent donc pas explicitement les accusations de Youtubeurs qui fustigeaient en juin dernier Apple, NVIDIA et Anthropic pour avoir utilisé leurs vidéos. En avril, OpenAI avait aussi subi les mêmes accusations.
En revanche, pour les données récupérées par AppleBot, ils assurent respecter les directives des fichiers robots.txt des sites demandant l'exclusion de l'indexation. Apple précise exclure les pages contenant des insanités et appliquer des filtres pour supprimer certaines catégories d'informations identifiantes.
À propos des contenus sous licences, considérés comme de qualité élevée, ils affirment s'efforcer d'en utiliser un « nombre limité ». Concernant le code sur lequel leurs modèles sont entrainés, les chercheurs utilisent du code provenant de GitHub sous licences MIT, Apache, BSD, CC0, CC-BY, ISC, Artistic et « sans licence ».
Pour les contenus spécifiquement liés aux mathématiques, Apple utilise deux jeux de données. L'un comprend des questions/réponses provenant du « web », dont une bonne partie de 20 sites riches en contenus mathématiques. Mais ils ne précisent pas quelles sont exactement les sources. L'autre regroupe tous types de contenus concernant les mathématiques (forums, blogs, tutos, séminaires...).
La recette d'entrainement d'Apple
Les chercheurs d'Apple expliquent avoir découpé la phase de pré-entrainement en trois étapes. La première est celle classiquement mise en place et la plus lourde en calculs. Dans la deuxième, ils réduisent la pondération associée aux contenus venant du web et de moindre qualité. Parallèlement, ils augmentent celles du contenu de code et des mathématiques en y ajoutant les contenus obtenus sous licence considérés comme de meilleure qualité. Enfin, la troisième étape consiste à allonger le contexte. Elle est similaire à la deuxième, mais effectuée avec une fenêtre de contexte plus large et en ajoutant des données synthétiques avec un contexte long.
Les modèles d'Apple ont été pré-entrainés sur des clusters TPU v4 et V5p (des puces de Google) avec le framework de l'entreprise AXLearn utilisant JAX. Plus spécifiquement, ils ont entrainé AFM-server sur 8 192 puces TPUv4 pour 6.3 Tera de jetons.
Pour AFM-on-device, ils se sont basés sur un modèle de 6,4B entrainé de la même manière qu'AFM-server, puis « élagué » et « distillé », deux méthodes connues pour améliorer les performances et l'efficacité de l'entrainement.
Concernant la phase de post-entrainement, Apple a utilisé des données annotées par des humains et des données synthétiques. L'étape semble complexe, car les chercheurs précisent avoir été obligés de mettre en place des procédures approfondies de curation et de filtrage des données pour obtenir des données de qualité suffisante. Ils détaillent dans leur document que ces données synthétiques leur ont notamment été utiles pour entrainer leurs modèles dans l'utilisation d'outils (comme l'appel téléphonique, l'interpréteur de code), la génération de code ou encore les mathématiques.
Sans trop de surprise, les auteurs expliquent que « la véritable mesure pertinente de la qualité [de leurs modèles] est la façon dont ils se comportent pour des tâches spécifiques sur l'ensemble de nos systèmes d'exploitation ». Ils affichent quand même quelques comparatifs d'utilisation :
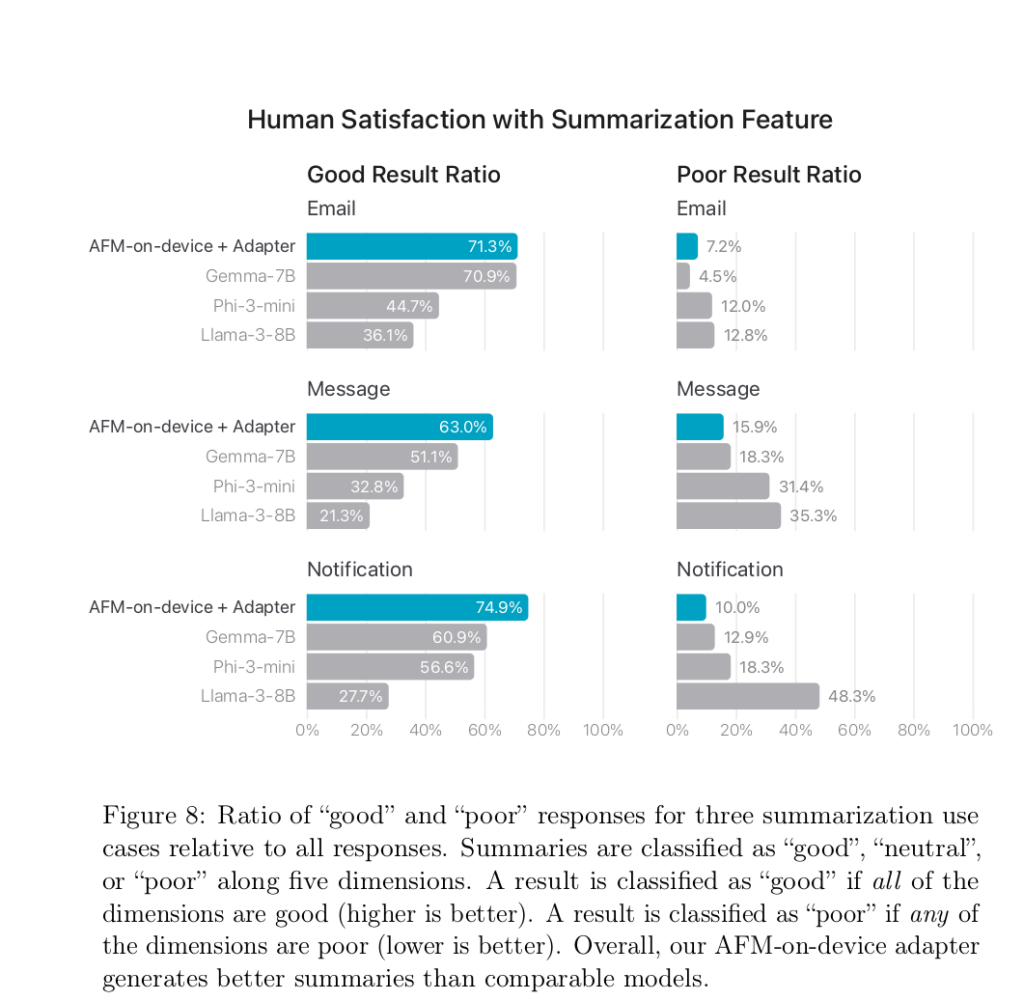

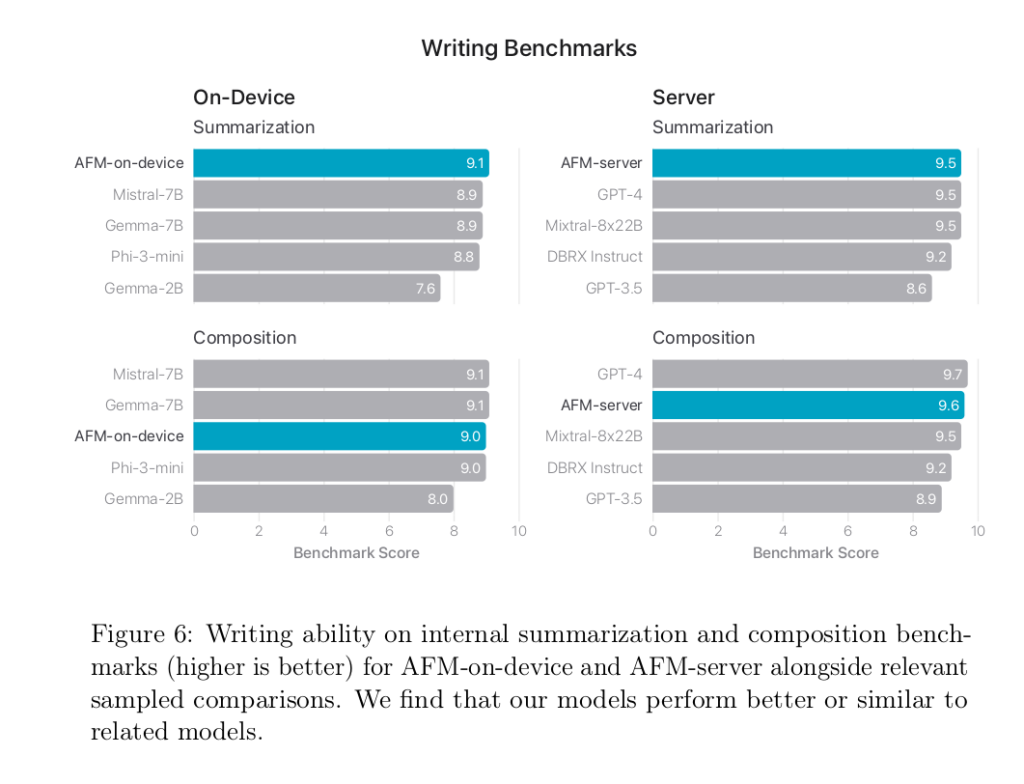
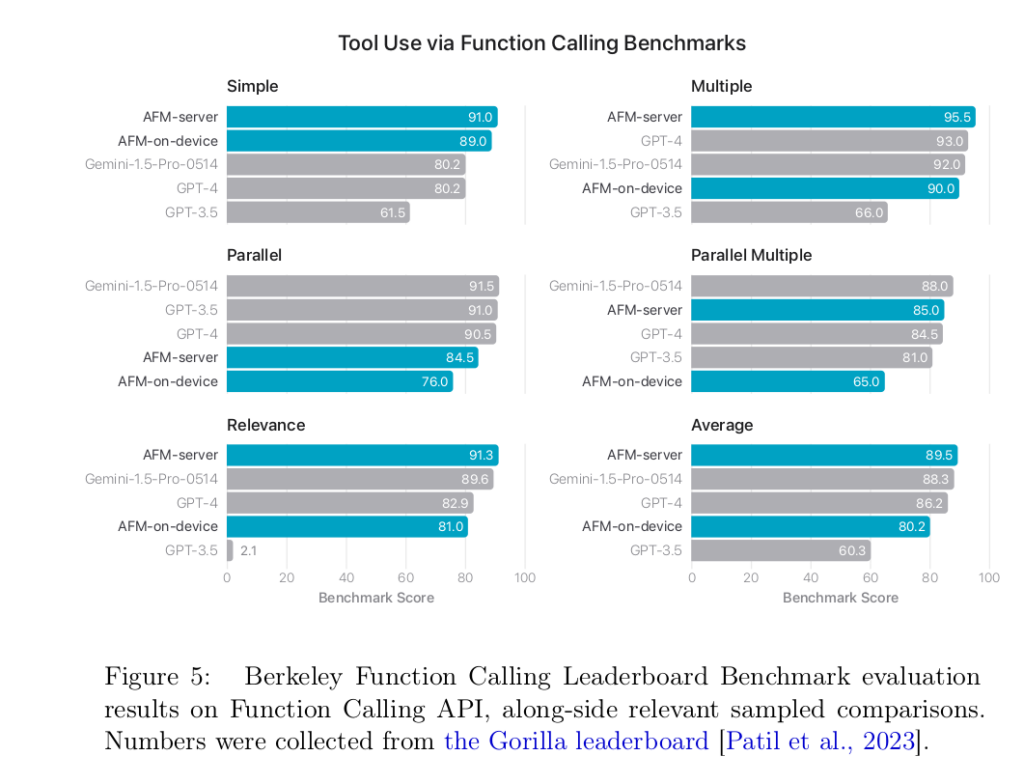
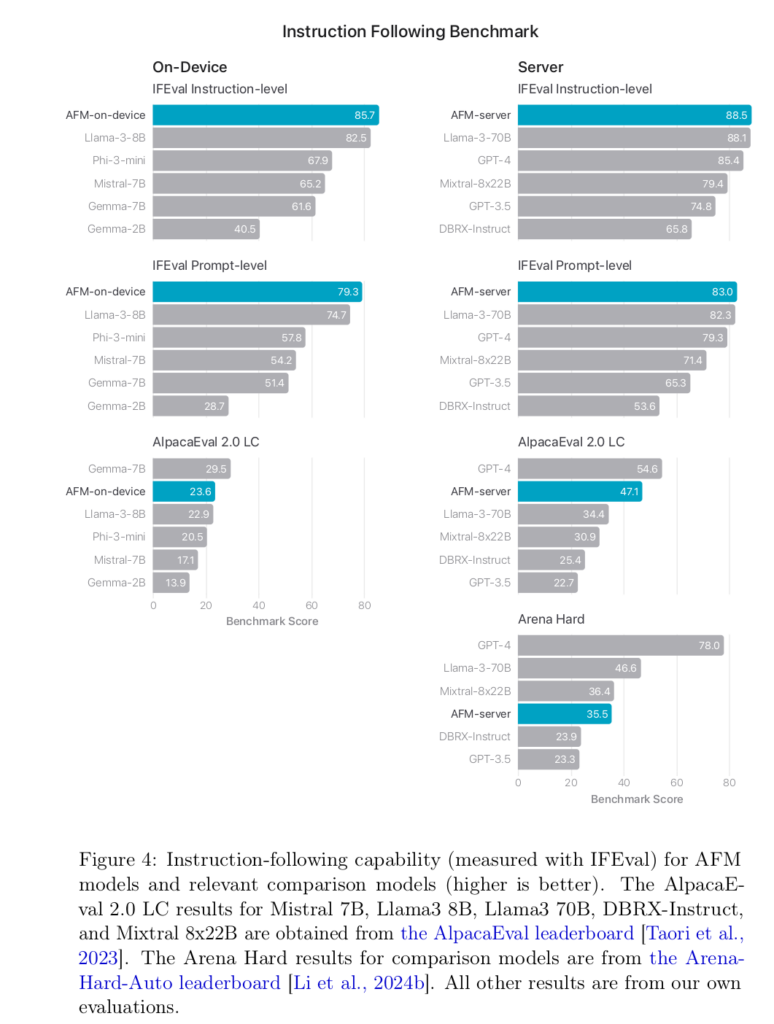
Et en conclusion, les chercheurs d'Apple appuient encore sur le fait qu'ils ont développé ces modèles pour « aider les utilisateurs dans leurs activités de tous les jours sur les produits Apple ». Un clin d'œil assez appuyé pour affirmer que la marque à la Pomme n'insère pas de l'IA dans ses produits seulement pour l'affichage.
Commentaires (6)
Vous devez être abonné pour pouvoir commenter.
Déjà abonné ? Se connecter
Abonnez-vousLe 31/07/2024 à 19h06
Le 31/07/2024 à 19h51
@Flock va croire que j'ai les idées tordues (après la pomme IA :
Avant de voir que c'est un homme vu du dessus, qu'il y a un visage et que le cerveau a une forme de pomme
:
Modifié le 31/07/2024 à 22h30
J'ai mis la qualité max et généré 4 photos avec comme prompt "do what you want".
Résultat 4 photos de paires de fesses floutées mais toutes différentes.
Modifié le 01/08/2024 à 08h38
Modifié le 31/07/2024 à 23h58
J'espère qu'une prochaine licence verra le jour permettant de restreindre l'usage du code publié pour l'entraînement des IA, tout en autorisant tout le reste.
Histoire de pouvoir limiter l'usage qui en est fait dans ce cas précis, comme avec les nouvelles déclarations dans les robot.txt, sans pour autant devenir une licence restrictive pour les autre aspects. Comme une nouvelle clause sur la Creative Commons par exemple.
C'est un manque je trouve actuellement, à moins qu'une telle licence existe (auquel cas je ne la connais pas).
Le 01/08/2024 à 11h13
Très malin aussi de concentrer tout le développement sur l'idée de faciliter l'utilisation de leurs OS (+ logiciels et recherche web, je suppose ?) et uniquement sur ça, un exemple que devraient peut-être suivre ses concurrents, au lieu de se disperser sur l'AI dite "générale" (sur ce dernier point, difficile - et fort coûteux - de concurrencer Popeye AI !
Dans mon exemple de Tonton Bernard, qui n'est vraiment pas calé en informatique ni très éveillé de la comprenette, je suppose que sa priorité serait de savoir comment faire ceci ou cela avec son appareil.
Exemple : Comment régler la luminosité / le grossissement de l'écran ? Comment créer une boite mail, envoyer / lire un mail ? Comment choisir / trouver / se rappeler de ses mots de passe ? Comment modifier / scanner / envoyer une photo rigolote pour l'anniversaire de Tata Suzette ? Comment sauvegarder / copier / effacer ceci ou cela ? C'est quoi le "Clownde ?