Intelligence artificielle : la CNIL veut (re)concilier « innovation et respect des droits »
À grands coups de dollars ?
concilier « innovation et respect des droits »")
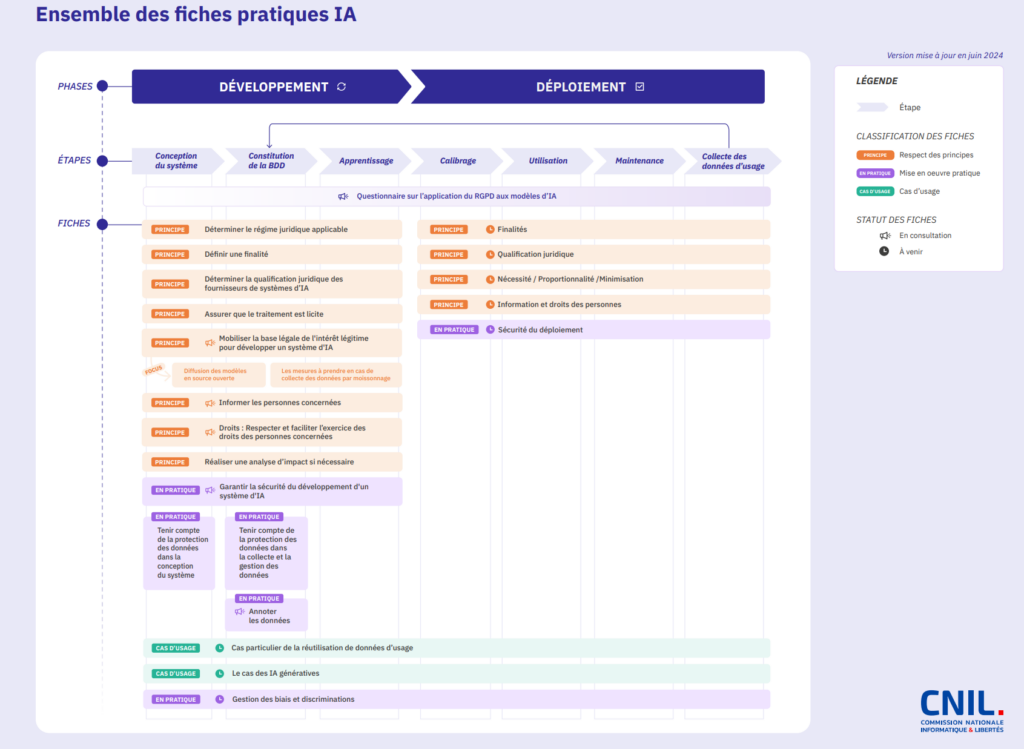
Dans son travail au long cours sur l’intelligence artificielle (générative), la CNIL vient de mettre en consultation sept nouvelles recommandations. Il y est question de base légale, d’information aux personnes, de sécurité… Un questionnaire sur l’application du RGPD aux modèles d’IA est aussi de la partie.
En mai de l’année dernière, la CNIL dévoilait son plan d’action « pour un déploiement de systèmes d’IA respectueux de la vie privée des individus ». Il s’agissait alors de répondre au lancement récent des IA génératives, ChatGPT en tête de liste.
Des fiches en avril, sept de plus en juin
En avril, la Commission nationale de l'informatique et des libertés publiait ses premières recommandations sur le développement des systèmes d’intelligence artificielle (SIA). Elles arrivaient après des rencontres avec des acteurs publics et privés, ainsi qu’une consultation publique de deux mois. Elles « permettent d’apporter des réponses concrètes, illustrées d’exemples, aux enjeux juridiques et techniques liés à l’application du RGPD à l’IA ».
Ainsi, il était notamment question de déterminer le régime juridique applicable, de définir une finalité et une base légale, d’effectuer des tests et des vérifications en cas de réutilisation des données, de tenir compte de la protection des données, etc. Sept fiches pratiques ont ainsi été mises en ligne il y a quelques semaines.
Comme prévu, une « nouvelle consultation publique sur le développement des systèmes d’IA » vient d’être lancée. Elle porte sur une seconde série de sept fiches pratiques. Elle est ouverte aux commentaires jusqu’au 1er septembre 2024. Le but : « aider les professionnels à concilier innovation et respect des droits des personnes »
- Base légale de l’intérêt légitime et développement de systèmes d’IA
- Intérêt légitime : focus sur la diffusion des modèles en source ouverte (open source)
- Intérêt légitime : focus sur le moissonnage (web scraping)
- Informer les personnes concernées
- Respecter et faciliter l’exercice des droits des personnes concernées
- Annoter les données
- Garantir la sécurité du développement d’un système d’IA
On ne va pas détailler l’ensemble des documents, surtout qu’ils portent bien leur nom pour comprendre de quoi il en retourne. Nous allons simplement nous attarder sur certains points.
Légitimité, nécessité et open source
Dans la première fiche, la CNIL rappelle que le recours à l’intérêt légitime est soumis à plusieurs conditions. On y retrouve notamment le fait que le traitement envisagé est « justifié par la condition de nécessité ». De plus, il ne doit « pas porter une atteinte disproportionnée aux droits et intérêts des personnes ». Des précisions sont apportées sur les notions de légitimité et de nécessité.
Sur la question des modèles open source, la Commission rappelle qu’on manque « d’une définition communément admise pour la diffusion d’un modèle d’IA en source ouverte ». On en parlait très récemment avec une analyse d’une quarantaine de modèles d’IA générative se prétendant « open ».
Si la publication des paramètres semble être « une condition minimale » pour la CNIL, d’autres points sont à éclaircir. Elle revient particulièrement sur la transparence du développement (documentation, code, données), le résultat (fiche descriptive, poids) et l’accès au modèle (bibliothèque, API, licence…).
Information aux personnes, sécurité
Sur l'information aux personnes, la CNIL rappelle que « les organismes qui traitent des données personnelles pour développer des modèles ou des systèmes d’IA doivent informer les personnes concernées ». Quelle que soit la méthode de collecte – directe ou indirecte –, l’organisme doit préciser son identité, la finalité et la base légale du traitement, les éventuels destinataires, la durée de conservation et enfin les droits (notamment d’introduire une réclamation) des personnes concernées.
Dans la dernière fiche, il est rappelé que « la sécurité des systèmes d’IA est un enjeu trop souvent mis au second plan par leurs concepteurs », alors que c’est une obligation prévue par l’article 32 du RGPD. Des mesures de sécurité sont détaillées dans le document.
RGPD vs IA
La CNIL rappelle – à juste titre – que les modèles d’IA « peuvent mémoriser une partie des données utilisées pour leur apprentissage. Différentes manipulations peuvent ensuite permettre de les extraire ». Cela soulève des questions quand on pense aux données personnelles.
Les modèles d’IA pourraient en effet « entrer dans le champ d’application du RGPD, y compris lorsque les risques pour les personnes sont limités ». D’autant qu’il « n’est pas toujours possible d’anonymiser les données d’entraînement, notamment dans le cas de certaines données non structurées ».
Dans sa remise en contexte de la problématique, la CNIL explique qu’il « ne semble pas possible de considérer que tous les modèles d’IA entrainés à partir de données personnelles sont par nature des objets anonymes ». Trois grands types de menaces sont mis en avant : régurgitation des données d’entraînement, inversion du modèle (attaque par reconstruction) et inférence d’appartenance.
Le questionnaire porte sur différents aspects : les risques de réidentification, les techniques permettant d'analyser les risques de régurgitation et d’extraction de données personnelles, l’application du RGPD et la responsabilité des acteurs.
La CNIL indique enfin que « les contributions seront analysées à l’issue de la consultation publique pour permettre la publication des recommandations définitives, sur le site web de la CNIL, courant 2024 ». D’autres publications sur l’IA sont prévues cette année, sans plus de détails.

Commentaires (0)
Abonnez-vous pour prendre part au débat
Déjà abonné ? Se connecter
Cet article est en accès libre, mais il est le fruit du travail d'une rédaction qui ne travaille que pour ses lecteurs, sur un média sans pub et sans tracker. Soutenez le journalisme tech de qualité en vous abonnant.
Accédez en illimité aux articles
Profitez d’un média expert et unique
Intégrez la communauté et prenez part aux débats
Partagez des articles premium à vos contacts
Abonnez-vous