Périphérie et brouillard : que sont les edge et fog computing ?
Non, pas Nogent-sur-Marne

Notre lexique sur le cloud :
Dans une première partie, nous avons vu les termes les plus importants du cloud, ainsi que ses concepts fondateurs. Cette fois, nous examinons deux autres concepts, assez liés : les informatiques de périphérie et géodistribuée, aussi appelées edge et fog computing.
- Perdus face au cloud ? On vous explique les notions principales
- Périphérie et brouillard : que sont les edge et fog computing ?
Edge computing : la banlieue de l’informatique
On pourrait dire, pour résumer, que l’edge computing est l’inverse du cloud. Ce serait pourtant une vue simpliste, car il lui est intimement lié.
La notion recouvre tout ce que l’on nomme « informatique de périphérie ». Cette périphérie s’établit par rapport au centre, qui est en fait le datacenter, comme nous habitons nous-mêmes la périphérie de la Voie Lactée par rapport à son noyau. En clair, si le cloud désigne le traitement des données dans le datacenter, l’edge computing désigne celui « sur place », à l’emplacement physique des utilisateurs, et donc à la source des données.
Mais alors, n’est-ce pas simplement de l’informatique classique sur site (« on premise » en anglais) ? Non, car l’appellation edge a été créée pour signifier une informatique de contact inscrite dans un contexte plus général de cloud. On parle ainsi souvent de cloud hybride, mélangeant le centre de données et des traitements sur site. De nombreuses sociétés se sont engouffrées dans ce contexte, dont Microsoft et Red Hat, car cette informatique de périphérie offre divers avantages, dont la souplesse d’adaptation vis-à-vis d’installations existantes.
Mais on aurait tort de résumer l’edge computing à un simple précurseur au cloud. On est bien sur une extension du cloud à tous types d’appareils et de dispositifs qui, sinon, auraient fonctionné exclusivement en local. La philosophie est toujours la même : la source de données effectue un premier traitement local des données, ou les envoie à un serveur proche physiquement pour cette opération, avant d’envoyer tout ou partie des informations au datacenter.
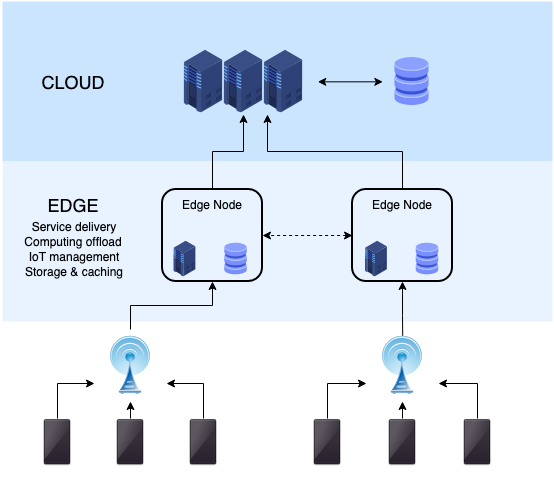
L’informatique de périphérie est pleinement liée aux objets connectés (IoT). Exemple simple : des capteurs dans une usine. Ils effectuent des relevés, dont les données sont envoyées à un serveur proche. Rien n’empêche l’envoi de ces informations plus tard au centre de données afin, par exemple, de produire différentes analyses. Mais le serveur local sera bien plus à même de prendre une décision rapide en fonction des relevés.
Il y a ainsi plusieurs avantages conséquents à ce découpage. D’une part, une réduction drastique de la latence, car la transmission des informations et des instructions en retour peut se faire par réseau local. L’état de la connexion internet et sa rapidité n’entrent pas en ligne de compte. D’autre part, une amélioration évidente de la sécurité, pour les mêmes raisons. Si des capteurs signalent une élévation dangereuse de la température dans une machine, on ne peut prendre le risque que la décision soit prise par une infrastructure n’étant peut-être même pas dans le pays. Même chose pour les véhicules autonomes : impossible d’attendre le résultat depuis un serveur, d’autant plus avec une connexion non garantie.
Enfin, l’edge permet une augmentation significative des performances dans plusieurs domaines. On peut ainsi déployer des structures locales sous chapeautage de règles précises, contrôlées depuis un centre de données. Les réseaux de distribution de contenu (CDN) déploient ainsi des serveurs proches physiquement des clients, pour un chargement plus rapide.
Fog computing : du ciel à la terre
L’appellation de « fog computing » – ou informatique géodistribuée – est plus récente, même si l’appellation remonte quand même à 2012. En 2015, le consortium OpenFog a même été créé par ARM, Cisco Systems, Dell, Intel, Microsoft et l'Université de Princeton, avant d'être fusionné avec l'Industrial Internet Consortium le 31 décembre 2018. Ce dernier travaille à la diffusion des technologies de l'internet industriel des objets (Industrial Internet of Things, ou IIoT).
Elle joue sur la notion de vapeur d’eau : elle compose les nuages comme le brouillard, mais ce dernier est au sol, donc proche. On peut le toucher. Si cette façon de voir était auparavant équivalente à l’edge computing, elle ne l’est plus vraiment. Elle désigne aujourd’hui une informatique de type cloud, mais distribuée et sur site, calée entre le cloud classique et la périphérie.

Dans une telle architecture, les données sont stockées et traitées sur place. Rien n’empêche dans l’absolu de s’adresser à un centre de données classique pour d’autres opérations, mais l’idée est précisément de s’en passer. La norme IEEE 1394 - 2018 la définit ainsi : « une architecture horizontale distribuant les ressources et les services de calcul, de stockage, de contrôle et de mise en réseau à travers tout le continuum cloud-objets ».
Ce brouillard a récemment fait l’objet d’une publication du CNRS. « Un cloud est typiquement constitué d’un grand centre de données, ou de plusieurs centres moyens, mais ce système arrive à ses limites car il est de plus en plus difficile de concentrer les ressources informatiques. On s’est alors rendu compte que transmettre des données très loin pour qu’elles soient traitées en masse dans de grands centres n’était pas toujours la meilleure solution », explique ainsi Guillaume Pierre, professeur à l’université de Rennes et membre de l’Institut de recherche en informatique et systèmes aléatoires (Irisa).
Le fog computing implique de travailler sur des problématiques spécifiques. Sa caractéristique majeure est l’adaptation, car il faut faire avec les moyens du bord et savoir exploiter au mieux ce qui est sur place, avant d’ajouter des équipements spécialisés. Par exemple, les centres de données ont le gros avantage de tout réunir sur place, dans un environnement ultra-contrôlé. Les transferts se font notamment par des connexions très rapides. Sur site, le fog computing devra souvent faire avec un mix entre les connexions : 4G/5G, ADSL, câble, fibre, etc.
Face à l’énorme consommation énergétique des datacenters, le fog computing peut également être une solution, même si « l’économie d’énergie n’est en général pas la raison première de préférer le fog computing, car ce système est pour l’instant moins bien optimisé que le cloud », ajoute Pierre Guillaume. Il précise cependant que l’efficacité énergétique de ces plateformes est étudiée.
Le fog computing pose d’intéressantes questions à une époque où l’usage-même est en réflexion. Outre le fait qu’un maillage de petites machines réclame moins de place et peut plus facilement être alimenté en énergies renouvelables, il donne matière à réfléchir sur le cœur de l’activité : l’ordonnancement.
Jean-Marc Pierson, professeur à l’université de Toulouse, directeur de l’Institut de recherche en informatique de Toulouse (Irit), spécialiste de l’efficacité énergétique des systèmes distribués et membre du Groupement de service pour une informatique éco-responsable du CNRS (GDS EcoInfo), pose la question : « Nous regardons aussi l’acceptation par les utilisateurs d’un service dégradé. Un service plus lent et des images de moindre qualité permettent d’importantes économies d’énergie. C’est presque une question philosophique : est-ce vraiment utile de solliciter immédiatement ces services chaque fois qu’on les désire ? ».
La question remet partiellement en cause la doctrine ATAWAD, pour « AnyTime, AnyWhere, Any Device » (« n’importe quand, n’importe où, n’importe quel appareil ».
Commentaires (7)
Le 27/01/2023 à 17h37
Cloud, Fog : j’aime bien cette métaphore filée.
J’attends l’équivalent du Cumulonimbus et du Thunderstom
Le 28/01/2023 à 11h47
J’ai entendu dire aussi que l’expression follow the sun pouvait s’appliquer au fog. C’est aussi une piste intéressante pour optimiser les coûts énergétiques. Est-ce que ça l’est vraiment… ^^
Dans tous les cas, tout ce qui tourne autour du cloud implique en grande majorité de louer et ne plus maîtriser.
Dans mon cas (clients type industriel qui dépassent jamais plus de 50 employés), on est sur des infra très modeste quasi full premise. L’architecture cloud est quand même plus complexe, ce qui est peut-être moins gênant pour les grands groupes qui ont les ressources pour suivre. Et puis ont est dépendant de toute une chaîne dont la partie réseau qui devient critique. Sauf que d’après mes derniers entretiens que j’ai eu avec Orange, les secours 4G passent par les antennes grand publique. En cas de panne d’un NRO ou d’un coup de pelle, on est pas à l’abri d’une congestion.
Le cloud c’est bien pratique mais il faut bien juger de la criticité du besoin et si ça s’y prête bien.
Le 28/01/2023 à 16h33
Et quand on se plante dans la conf d’un routeur, tout le beau nuage s’assombrit :
https://www.bleepingcomputer.com/news/microsoft/massive-microsoft-365-outage-caused-by-wan-router-ip-change/
Ça doit probablement être ça “Thunderstorm”
Le 29/01/2023 à 09h48
C’est la même idée que la sarcellite ou la flatneurose. À ces titres, il y aurait alors urgence à revenir au pavillon ou à la dernière folie.
Le 03/02/2023 à 09h28
Merci NXI !
Ça m’agace cette mode de parler de “on premise” depuis quelques années, alors que c’est l’hébergement normal, et qu’on peut dire “sur site” ou local.
Des infras entièrement locales, tu veux dire.
Le 03/02/2023 à 12h12
Oui, ou les deux. Locales avec des produits on premise
Le 03/02/2023 à 14h47
“on premise”, ça veut dire “sur site”, autrement dit local.