CXL, DDR5, HBM, persistante : la mémoire évolue, VMware s’adapte avec Capitola
Disaggregate everything

Notre dossier sur VMworld 2021 :
Dans la transformation en cours du serveur tel qu'on le connaît, la mémoire était un élément à peu près épargné, mais cela commence à changer. Avec Optane, Intel avait donné le coup de semonce. CXL et les modules M3 enfonceront le clou. De quoi inciter des acteurs comme VMware à tout repenser.
Des processeurs, leurs contrôleurs mémoire, quelques E/S et autres lignes PCI Express pour les périphériques et le stockage, voilà ce qui définit le plus souvent un serveur, encore aujourd'hui. La tendance à l'hyperconvergence (HCI) qui a agité le marché ces dernières années a d'ailleurs renforcé cette façon concentrée de voir les choses.
Le serveur change (et ce n'est pas sale)
Mais avec la montée en puissance du PCI Express, de nouveaux protocoles comme CXL ou le NVMe-oF, des technologies à mi-chemin entre mémoire et stockage, du réseau à plusieurs centaines de Go/s, tout est en train de changer. Désormais, il faut tout « désagréger », pour mieux adapter les machines à des besoins spécifiques.
Ce n'est pas tant une marche inverse qu'une manière de penser l'hyperconvergence autrement : non plus au niveau du simple serveur, qui est désormais plus modulaire, mais à celui du cluster qui devient l'entité à tout faire. Les données s'y échangent, se répliquent, de manière cohérente et hautement disponible.
Pour y parvenir, AMD et Intel préparent de nouvelles plateformes : Zen 4 pour l'un, Sapphire Rapids pour l'autre. Avec tout un écosystème de solution autour d'eux pour mettre cette stratégie en musique. Avec son projet Capitola dévoilé à l'occasion du VMworld 2021, VMware a d'ailleurs prévenu : il faudra compter avec lui.
- VMWorld 2021 : des évolutions profondes, par-delà les promesses des Cross Cloud Services
- CXL, DDR5, HBM, persistante : la mémoire évolue, VMware s'adapte avec Capitola
Au commencement était Optane
Lorsqu'Intel et Micron ont dévoilé 3D Xpoint en 2015, on ne se doutait pas à quel point cela pourrait mener à changer la perception que l'on peut avoir de la mémoire au sein d'un serveur. Et si le projet a connu de nombreux déboires depuis, sans trouver réellement son chemin dans l'offre grand public, il a posé les bases de la mémoire persistante.
Un concept né quelques années plus tard avec les modules Optane au format DIMM, désormais connu sous le nom de PMem de série 100 (Apache Pass) ou 200 (Barlow Pass). De quoi permettre d'ajouter jusqu'à 4 To (8x 512 Go) à 2 To (8x 256 Go) de DDR4 pour atteindre 6 To de mémoire adressable. Les débits annoncés par Intel pour sa dernière génération sont de 8,1 Go/s en lecture, 5,6 Go/s en écriture. Le TDP de 15 watts.
Pourquoi en arriver à de telles capacités ? Tout simplement parce que cela devient nécessaire du fait de l'augmentation continue de la densité au sein des serveurs, mais aussi par la taille des jeux de données à traiter dans le monde du HPC ou de l'IA. Il faut du gros débit, de la faible latence, au-delà de ce que proposent les SSD.
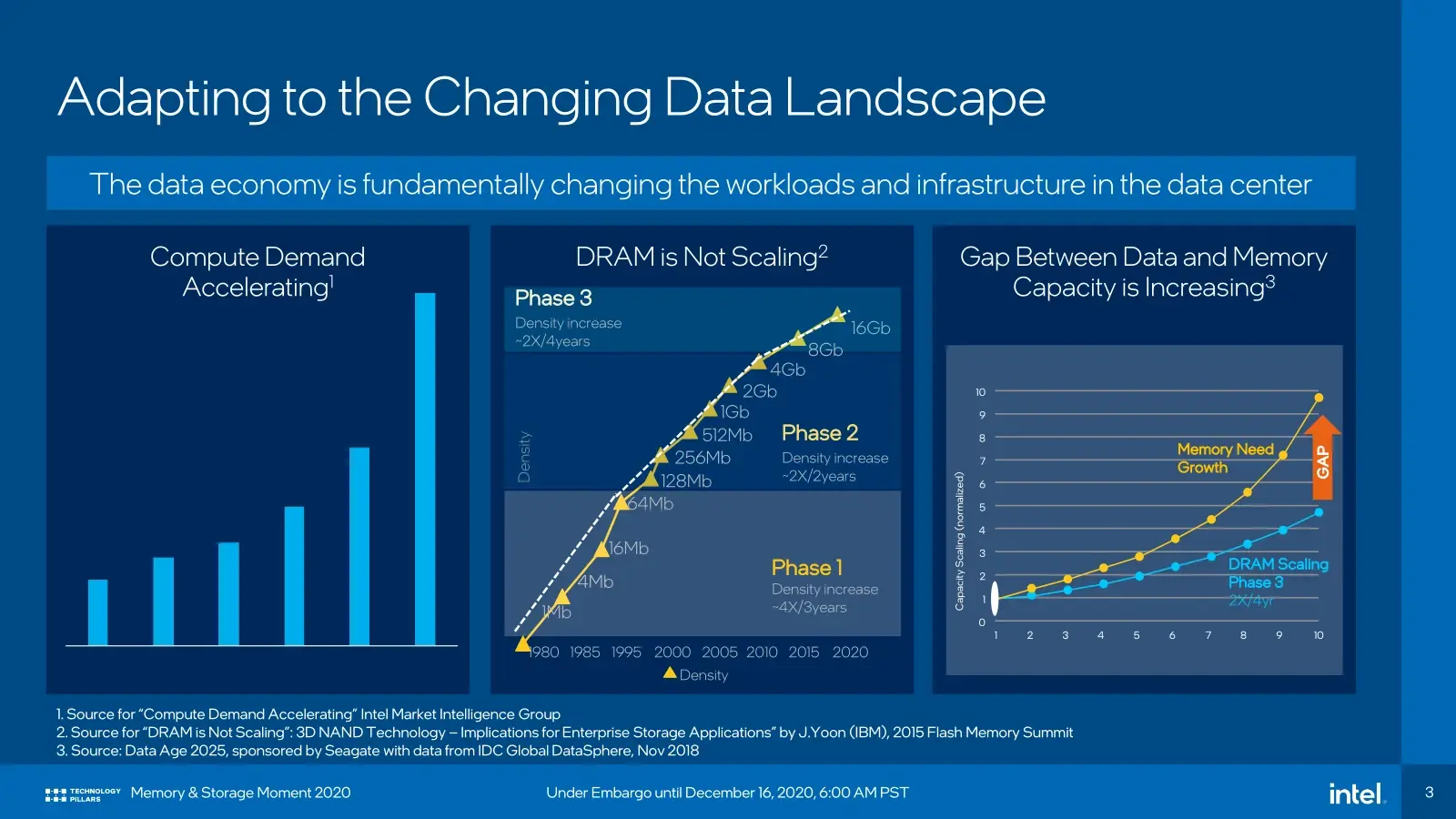

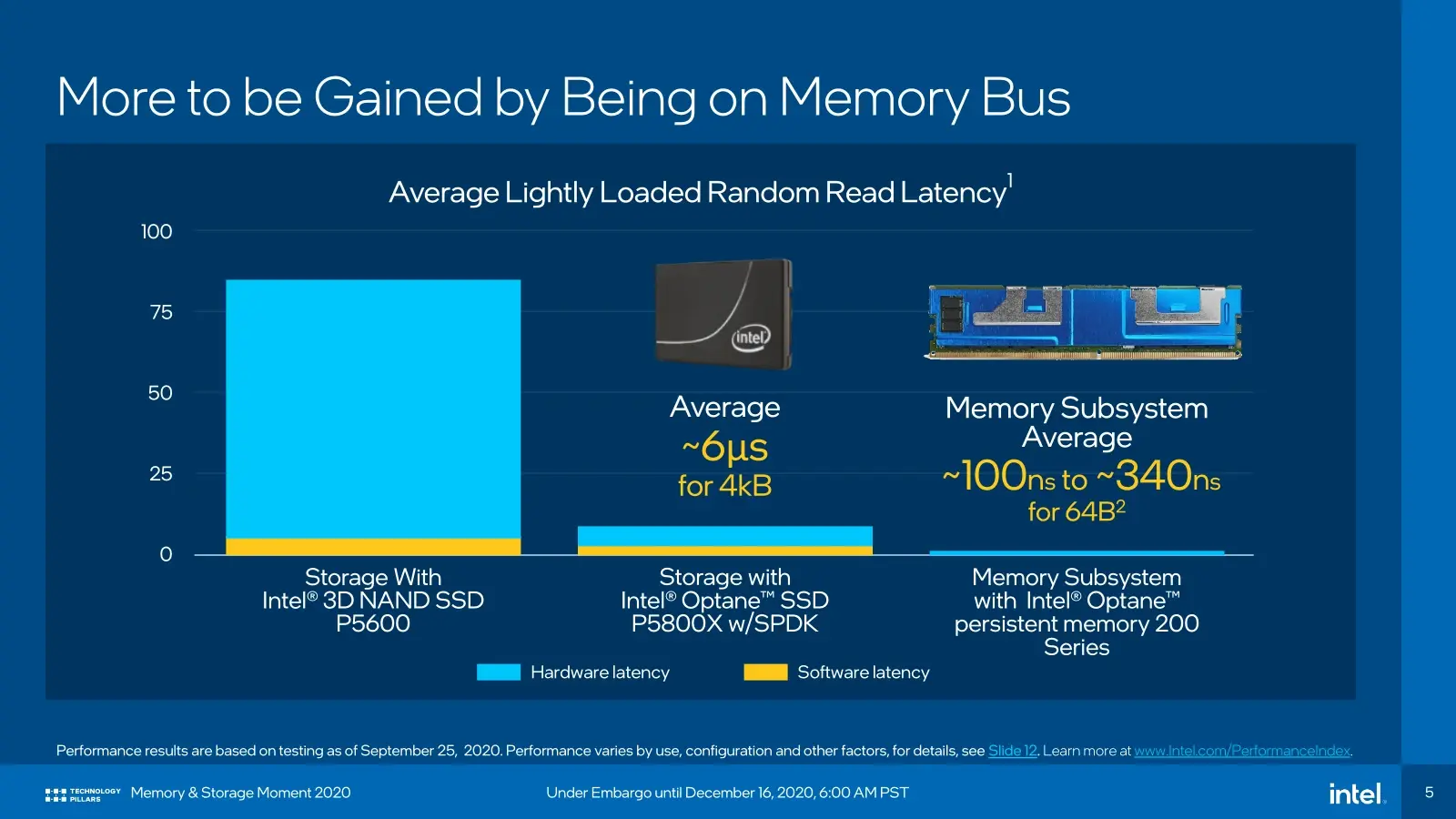



Les modules Optane PMem peuvent pour rappel être reconnus et gérés par le système comme de la mémoire classique, mais avec une latence plus élevée du fait qu'ils sont basés sur des puces 3D XPoint. Elle reste néanmoins bien plus faible que celle d'un SSD classique, profitant de leur conception et de l'interface directe avec le CPU via les ports DIMM. Bien que coûteux, ces modules ont aussi l'avantage d'être plus abordables au Go que de la DDR4.
Avec Sapphire Rapids, Intel ira plus loin puisque le constructeur y intègrera un contrôleur DDR5 mais pourra également gérer de la High Bandwidth Memory (HBM) sur certaines références. Optane pourra également venir accompagner l'ensemble avec la série 300 (Crow Pass). Puis la série 400 (Donahue Pass) pour Granite Rapids.
D'ailleurs, les concurrents ne s'y trompent pas et travaillent à des solutions plus ou moins similaires. On l'a encore vu récemment avec l'annonce des FL6 par Kioxia, même s'ils ne sont pas encore au niveau.
CXL change la donne
Certains tentent le coup d'après, comme Samsung qui a récemment annoncé son Memory Expander. Il s'agit d'un module de DDR5 qui ne se connecte pas directement sur la carte mère puisqu'il est au format E3.S. Il s'agit donc d'un lien PCIe x16 profitant du protocole Compute eXpress Link (CXL) pour la cohérence mémoire, qui permet à un système hôte de l'utiliser comme s'il s'agissait de sa propre DDR5, gérée par le contrôleur du CPU.


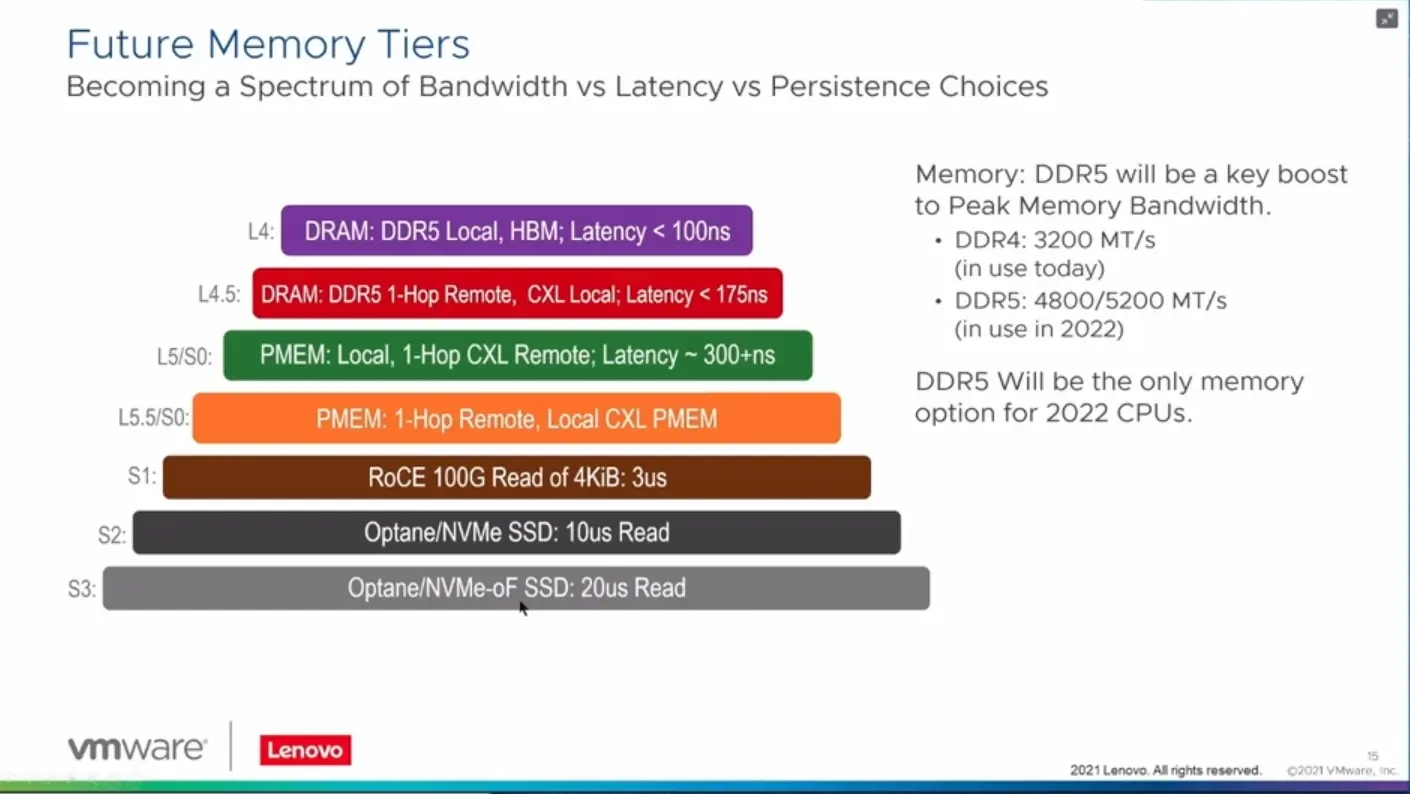




Ici aussi la latence est plus élevée (dans les 300 ns) et on perd l'avantage de modules moins coûteux, mais on peut en ajouter autant qu'il y a de lignes PCIe disponibles, souvent bien plus que de canaux mémoire.
Autre possibilité offerte par CXL : la gestion en pool de mémoire au sein de clusters où différents serveurs et composants peuvent partager leur mémoire via le réseau, un peu comme pour le stockage via NVMe-oF, quel que soit le mode de connexion locale. Le PCIe, CXL et des formats comme l'E3 permettant de connecter tant du stockage que de la mémoire ou des accélérateurs, ils peuvent agir de manière concertée et unifiée au sein d'un même cluster. Ce, même s'ils sont organisés via une somme de serveurs spécialisés.
Il faudra néanmoins veiller à concevoir de telles architectures selon les besoins de performance, le réseau et la latence imposée par la « distances » ayant leurs limites.
VMware prépare son projet Capitola
Certains s'y préparent déjà, notamment VMware qui a dévoilé son projet Capitola à l'occasion du VMworld 2021. L'éditeur dit rencontrer de plus en plus de demandes de la part de ses clients (principalement de grosses entreprises) qui réflechissent à la manière d'augmenter la capacité en mémoire de leurs infrastructures.
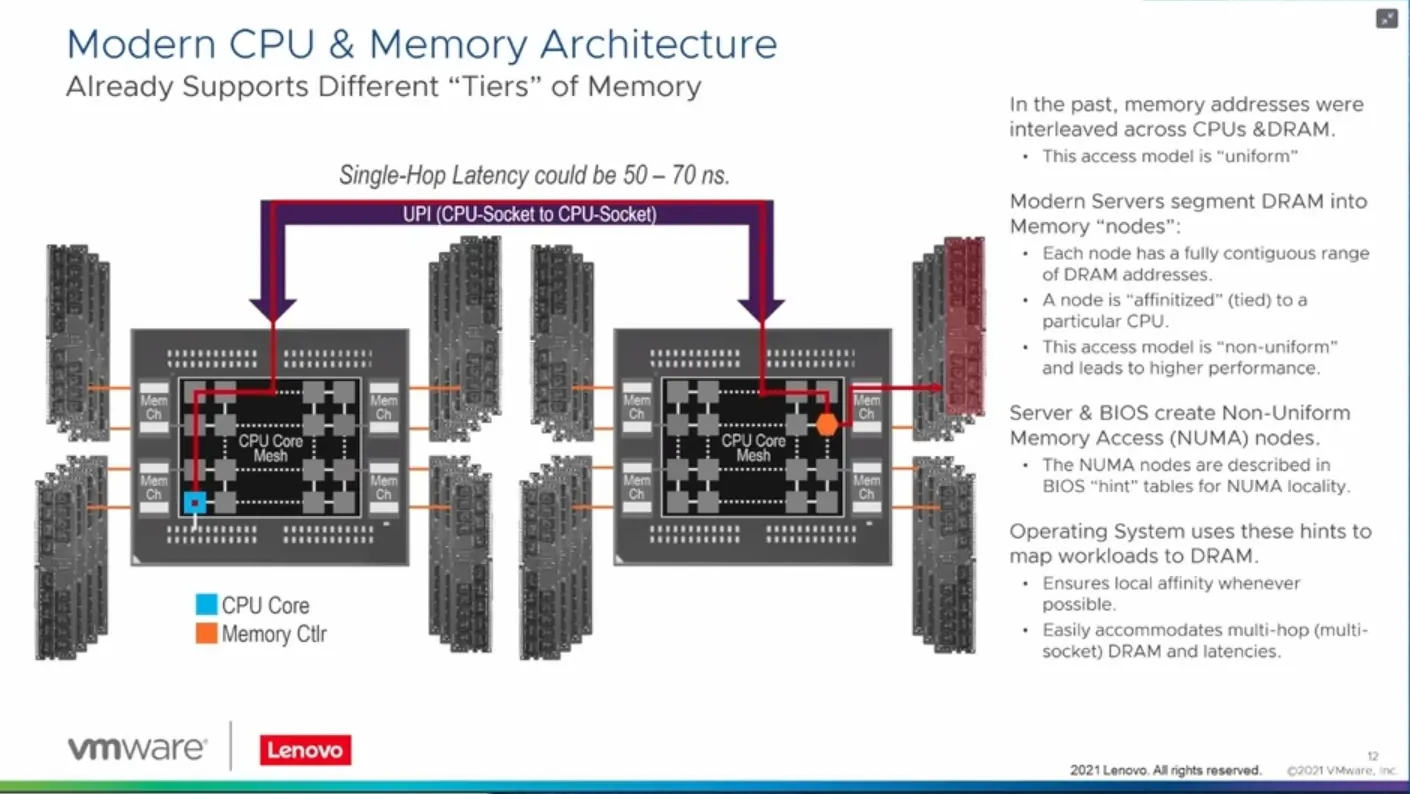
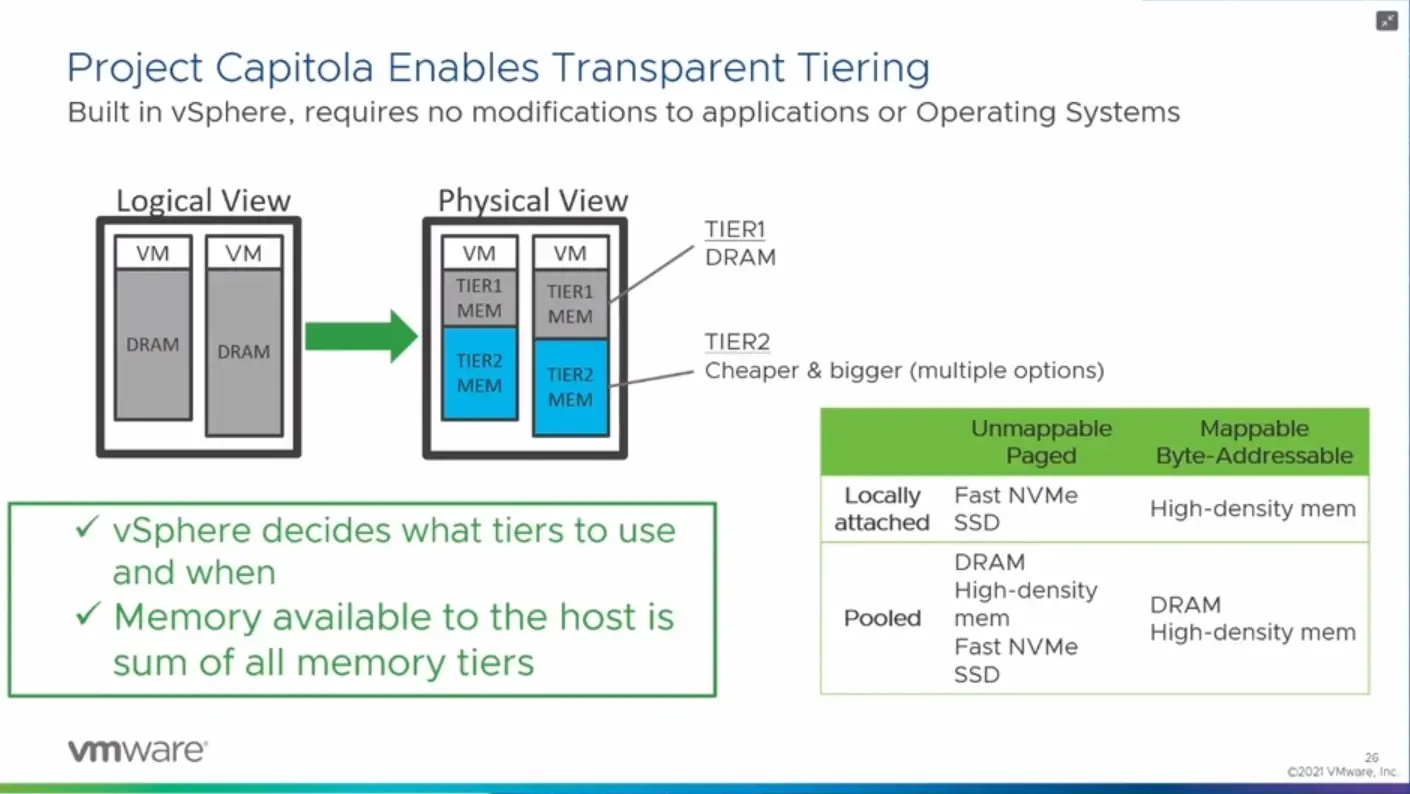
Si les systèmes ont déjà l'habitude de gérer différents niveaux d'accès aux données, avec des latences et débits différents, que ce soit à travers les différents niveaux de cache d'un processeur, puis sa mémoire qui peut être connectée via différents dies/sockets, des modules PMem ou du simple stockage, l'arrivée prochaine de HBM, de CXL et de modules comme le Memory Expander de Samsung changent la donne.
Avec Lenovo, VMware a donc travaillé à une nouvelle version de son hyperviseur capable de reconnaître et de gérer ces différentes solutions, puis de les utiliser de manière « intelligente ». Lors de la session de présentation de cette technologie, une démonstration a été faite d'un serveur à deux CPU, l'un avec 128 Go de DDR5, l'autre avec 16 Go accompagnés de 128 Go via les modules E3.S de Samsung. Soit un total de 272 Go.
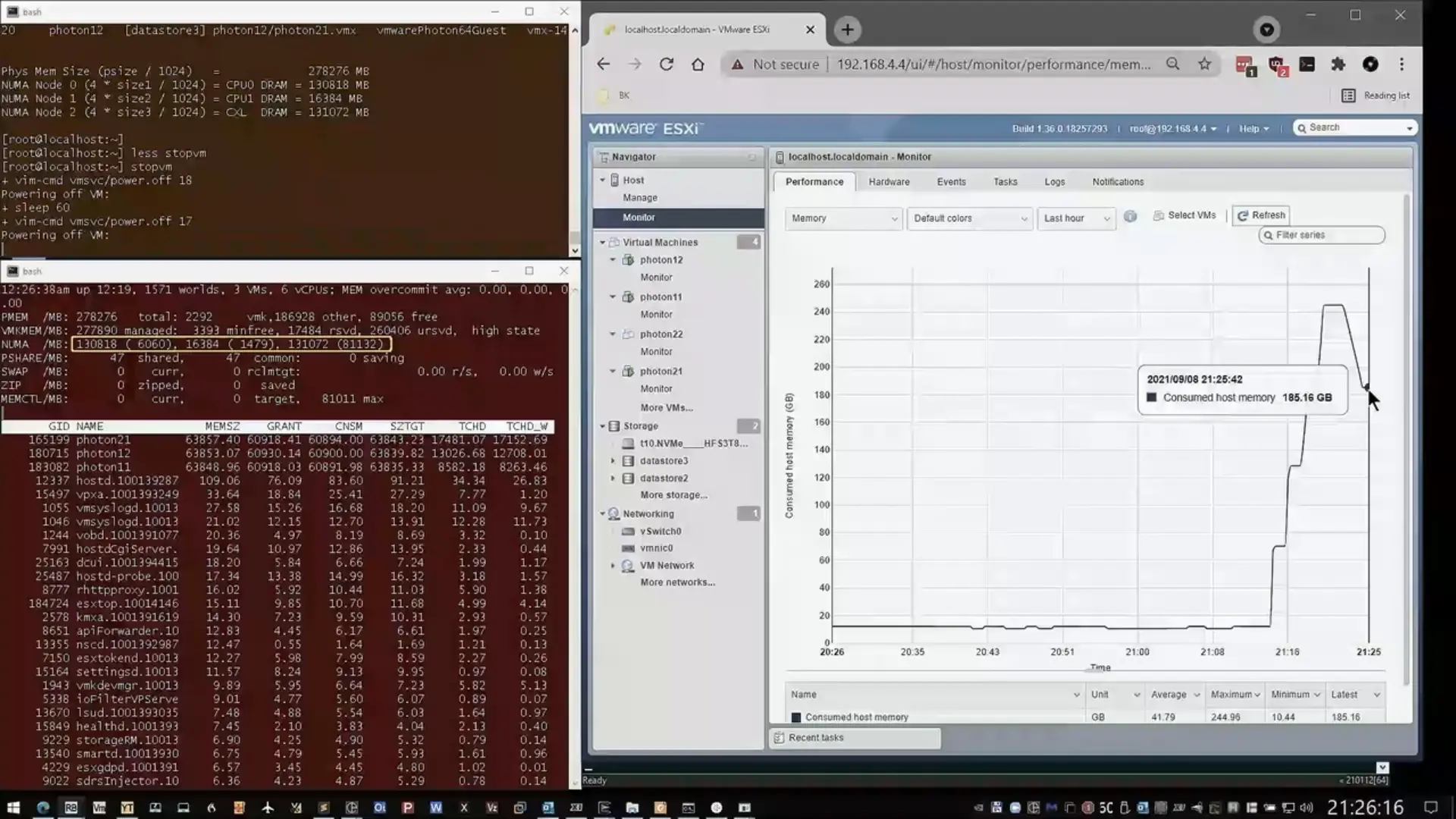

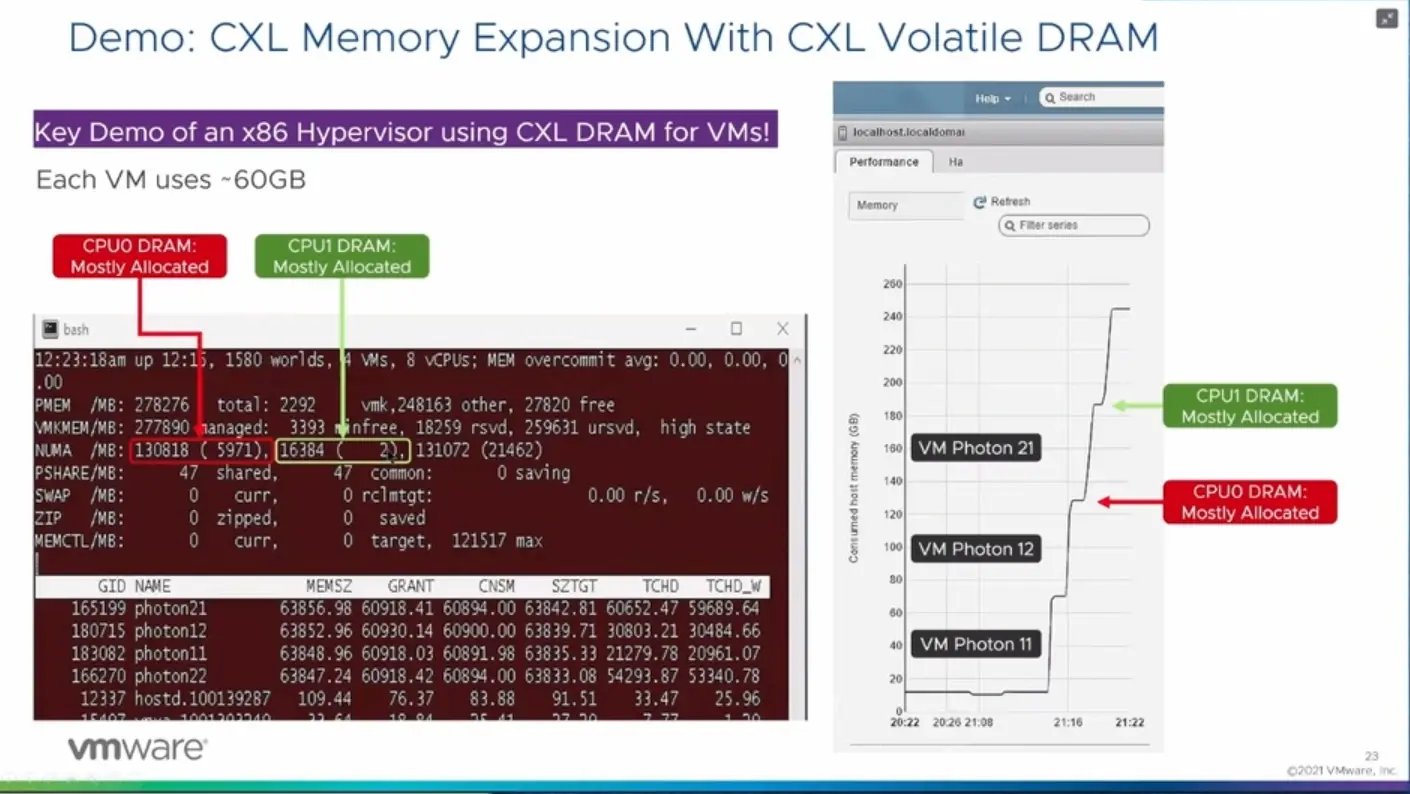




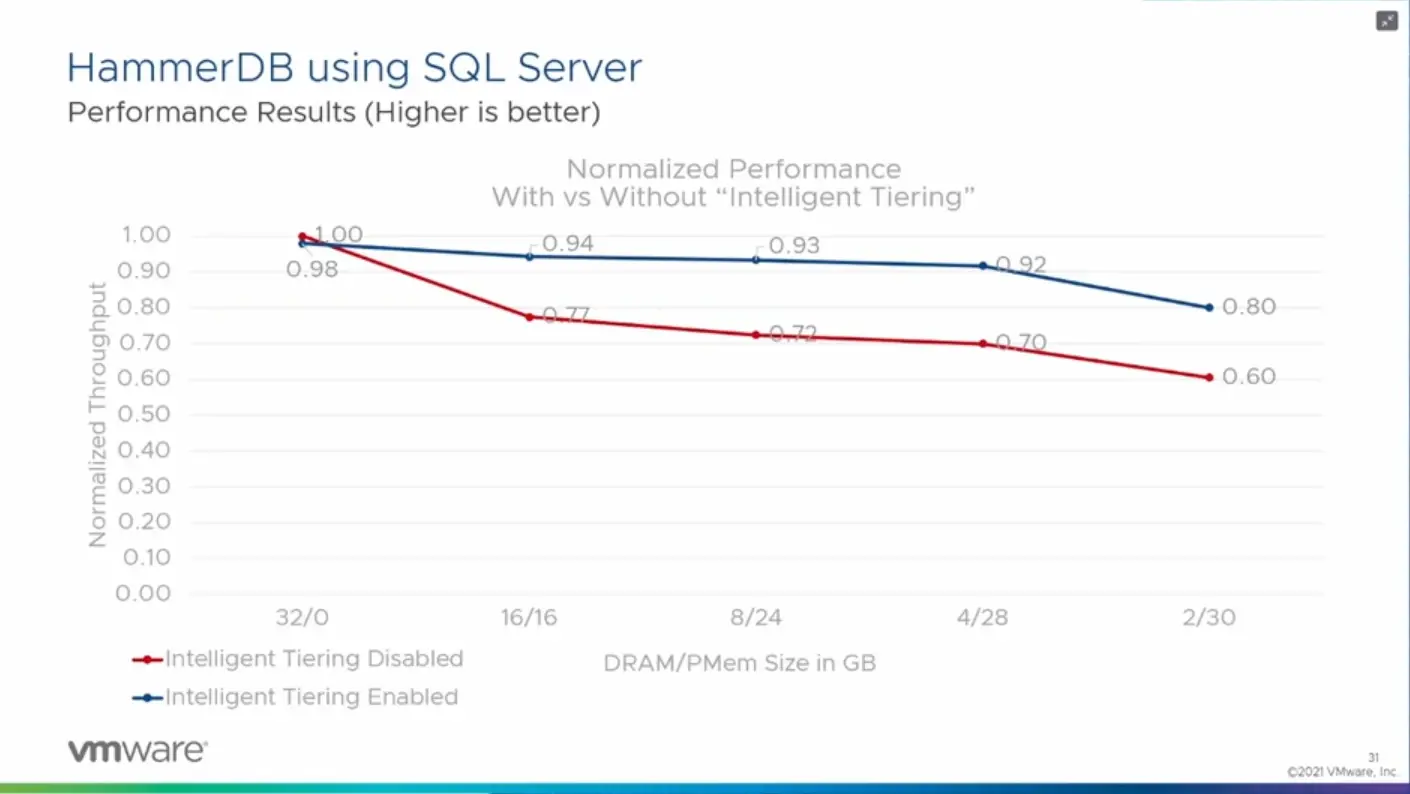


Des machines virtuelles disposant de 60 Go de mémoire chacune ont alors été créées, occupant peu à peu la mémoire locale, puis les modules CXL, sans intervention particulière de l'utilisateur, tout était transparent. Il sera intéressant de voir si une machine virtuelle peut se « déplacer » de la mémoire classique à ses modules selon ses besoins en termes de performances par exemple, mais il est encore un peu tôt pour évoquer de telles possibilités.
Pour rappel, Sapphire Rapids et CXL ne sont pas attendus avant le début de l'année prochaine, Zen 4 dans la seconde moitié de l'année. C'est sans doute à ce moment-là que Capitola débarquera dans vSphere/ESXi.
Commentaires (10)
Vous devez être abonné pour pouvoir commenter.
Déjà abonné ? Se connecter
Abonnez-vousLe 11/10/2021 à 17h34
Attend… Est-ce que ça voudrait pas dire qu’à “terme”, et avec quelques évolutions technologiques, les slots DIMM pourraient disparaître du paysage ?
Je veux dire, si les CPU réduisent la latence sur les lignes PCI, les slots PCI pourraient devenir la prise USB de l’intérieur des PC. RAM, stockage, GPU, réseau, etc.
Ca pourrait simplifier énormément de choses.
Je suis pas crédule, je sais qu’on en est encore loin, mais ça me semble pas une idée totalement idiote. RDV dans 5 ans pour voir si on se dirige vers ça :)
Le 11/10/2021 à 17h49
C’est pas impossible mais improbable à court terme je pense. Les DIMM restent proche du CPU donc à faible latence (50 ns environ, ça dépend des plateformes) avec un gros débit. La latence répond aussi à des contraintes physiques.
Mais on peut imaginer que ce soit vu comme un cache de niveau 4 avec le pool mémoire qui serve pour le gros du traitement des données à plusieurs To comme ça peut être le cas du stockage actuellement. La question ce sera alors de quoi se compose le pool : de modules à la Samsung ou d’Optane ?
Mais oui, le PCIe c’est déjà l’usb du serveur. D’ailleurs je serais pas contre qu’on remplace les clés USB par des modules E1.S dans le grand public cA une époque on avait des HDD extractible dans presque tous les PC, ça manque
cA une époque on avait des HDD extractible dans presque tous les PC, ça manque 
Le 11/10/2021 à 17h52
Boah, tu sais, les connaissant, ils vont obligatoirement passer par un port spécifique, le “E1.S express”, accessible uniquement en facade.
Mais sinon, ouais, ça pourrait être cool ! :)
Le 11/10/2021 à 18h01
Ah ah, c’est pas nécessaire pour le coup, c’est PCIe, hot plug, facile à adapter et 4x/8x ready. Rien que pour les fabricants de NAS ce serait un choix intéressant. Mais il faudrait attendre que ça se démocratise, donc sans doute pas tout de suite
Le 12/10/2021 à 07h25
Je pense que ça peut être une sacrée évolution pour les bases de données in memory (SAP Hana) : Actuellement on a des machines monstrueuses uniquement pour adresser la RAM nécessaire (mini 1-2to pourt un petit client)
Du coup on se retrouve avec une débauche de CPU qui se tournent les pouces tout en ayant probalement pas mal de cycles perdus à se synchoniser entre CPU.
Avec ce système on augmente beaucoup la densité mémoire, et Hana sait déjà gérer les tiers mémoires : actuellement il gère trois tier :
Donc on pourrait imaginer des nuances de “chaud” selon que la RAM soit plus ou moins proche du CPU. Les données les plus requetées restant au chaud à quelques cycles du CPU, les autres débordant petit à petit sur les tiers de mémoire PCie, puis optane et enfin SSD…
Le 12/10/2021 à 07h32
Oui c’est un peu le but et l’usage typique qui est visé par tout ce qui touche à la désagrégation mémoire, pouvoir opérer une bonne partie des données en RAM ou équivalent sans forcément avoir besoin de X CPU par volume de RAM si ce n’est pas nécessaire (ou parce que c’est le GPU ou un accélérateur qui traite par exemple). Et du coup faire un peu remonter le “data lake” dans la chaine alimentaire du stockage de données, que ce soit via de la RAM (pour les riches) ou des solutions intermédiaires (pour les autres).
Le 12/10/2021 à 07h39
C’est effectivement le travail sur les bases de données actuelles.
Par exemple dans le cas de SQL Server, Ms a travaillé pour que SQL Server gère le mapping mémoire lui-même, se substituant à la gestion mémoire de Windows, ceci afin de ne jamais swapper.
Avec des mémoires lentes et rapides, rien n’empêche de le faire niveau système: la RAM classique et la NV peuvent être dans l’espace d’adressage du système, un système de cache aidant à ne pas lire deux fois ou différer les écritures, sans que le programme sache quelle est la part de RAM et la part de NV.
En fait, j’ai déjà vu cela en 2000, mais avec 2 types de RAM: RAM rapide et RAM lente, sur une silicon graphics qui avait 64CPU et 64Go de RAM: à l’époque 64Go de RAM rapide, ça aurait fait fondre le truc.
L’ordonnanceur utilisait la RAM rapide moitié comme de la RAM, moitié comme de la cache. Pendant un appel pour écrire dans la RAM lente, le temps que la RAM lente donne l’accès, il pouvait encore modifier la copie en RAM rapide et n’écrire que quand la lente était prête.
Le 12/10/2021 à 10h03
La capacité RAM sur un serveur 1U (bi-socket) est de 3To - 24 x 128 Go de RAM - et 6To pour du 3U (quad-socket)
(il faut bien évidement des CPU gérant 1.5To ou plus…)
Même constat pour moi, les seuls gros consommateur de RAM sur les bare metal dédiés sont pour SAP HANA. Ces consommateurs de serveurs physiques ne sont jamais sur la capacité max ci-dessus.
Plutôt sur :
1.5To RAM pour serveur 1U (max* serait à 3 To)
3 To RAM sur du serveur 3U (max serait* à 6To)
*Sous réserve que la capacité max soit dans les gabarits SAP HANA qui sont restrictifs (je ne les ais pas sous les yeux mais il sont assez restrictifs - par exemple du 2To RAM est hors gabarit).
Je ne connaissais pas les tiers que tu décris, mais si les débits RAM CLX sont 2 à 3 fois plus lent que la RAM classique, je ne pense pas qu’elle la remplacera ou s’additionnera à la classique : elle serait surement sur un tier différent ?
Et étendu aux autres besoins sa risque d’être la même chose ?
Sa semble bien être une évolution et non une révolution
Je me répète mais j’ai l’impression que les nombre de slots et lane PCI sont plus bloquant que les slot ram actuellement, dans beaucoup de cas.
=> Quoiqu’il en soit il y aura forcement des consommateurs, en espérant que la diffusion/adoption soit suffisamment importante pour éviter d’avoir quelques serveurs “verrue” avec des technos qui ont fait des flops
Le 12/10/2021 à 10h47
CXL c’est quand même la prochaine techno intégrée aux plateformes d’AMD, ARM et Intel, en plus de tout l’écosystème qu’il y a autour, en étant basé sur PCIe, on est loin de la “verrue” faite dans le coin de l’esprit d’un constructeur isolé. D’autant que comme tu le dis, il y a pour le moment une corrélation directe entre la capacité et le nombre/type de CPU, que certains aimeraient bien dépasser.
Pour le reste comme évoqué, des modules tiers n’iront jamais au débit/latence de la DIMM, mais entre des centaines de Go/s à 50 ns et quelques Go/s en dizaines de µs il y a la place pour des éléments intermédiaires. Reste à voir lesquels et comment les gérer, avec quel coût au To (qui reste le point faible de la mémoire, même si certains sont plus contraints par la physique des serveurs que l’aspect coût).
Le 13/10/2021 à 06h22
Certainement un tiers différent, y’a différent mode de paramétrage en fait, le mode data température, où tu “ranges” tes tables selon leur accès les données qui doivent être accédées rapidement dans le tiers chaud… Le jeu étant d’éviter de faire des jointures entre différents tiers, encore que ça marcherait bien tant que tu ne requètes pas un champ “froid”.
Et le mode plus classique en débordement, tout est en chaud (ram) et les données les moins accédées débordent sur le tiers d’en dessous quand il est plein.
A noté je crois que ces tiers sont gérés dans la base Hana, mais pas (encore ?) dans la couche applicative S/4HANA :) https://blogs.sap.com/2019/03/07/recommended-data-tiering-approaches-for-sap-and-native-applications/
La “limite” pour le hardware officiel est à 24To : https://www.sap.com/dmc/exp/2014-09-02-hana-hardware/enEN/#/solutions
 Google
Google
Et il me semble avoir vu un slide de Google qui a monté une instance en prod à 96To de RAM pour Visa je crois :)